プログラミング言語Pythonに限らず、多くのプログラミングは実行環境を構築する必要があります。
ここでは、アカデミック分野やデータサイエンス分野で分析に利用されるJupyter Notebookを解説します。
- Python実行環境の構築方法を知りたい人
- Jupyter Notebookのインストール方法が知りたい人
- Jupyter Notebookの使い方/利用方法を理解したい人
上記の悩みを解決しながら、Python実行環境であるJupyter Notebook(ジュピターノートブック)のインストールから使い方まで解説します。
Pythonの実行環境構築でつまずくと取り組みが遅れるため、ハンズオン形式で実施できるようまとめています。
▼【無料教材】Pythonを学びたい人へ資料を配布中▼
本記事をお読み頂いているプログラミング初学者向けに、本サイトはPythonを始めるためのガイドを配布しています。
以下に無料配布するPython資料をご紹介します。
- Python入門ガイド
- Python製デスクトップ用GUIライブラリガイド
- Python用学習ロードマップシート
- Tkinter製テンプレート集
- DXアイデア100選スライド
限られた時間を情報収集に極力かけず、他言語よりも「なぜ今Pythonを選ぶべきか」をガイドにしています。
プログラミングにおいて、情報収集の時間短縮は学習時間の短縮に直結します。
開発環境→基礎学習→ライブラリ/FW→アプリ開発に至る学習シートを配布しています。
また、定期アンケートによって「リアルな声」を反映して常に教材改善のアップデート情報を受け取れます。
\ メルアドのみで今すぐ受け取れます /
Python学習ロードマップによる具体的な学習手順
これからPython学習を始めるにあたって、回り道せず効率的なプログラミング学習を実施したい人は多いです。
Python学習において、学習手順を示すロードマップ化は必須です。
- 学習範囲の全体像を把握/理解
- 学習期間中の時間配分などに有効
以下は、学習手順を把握するためのPython学習ロードマップになります。
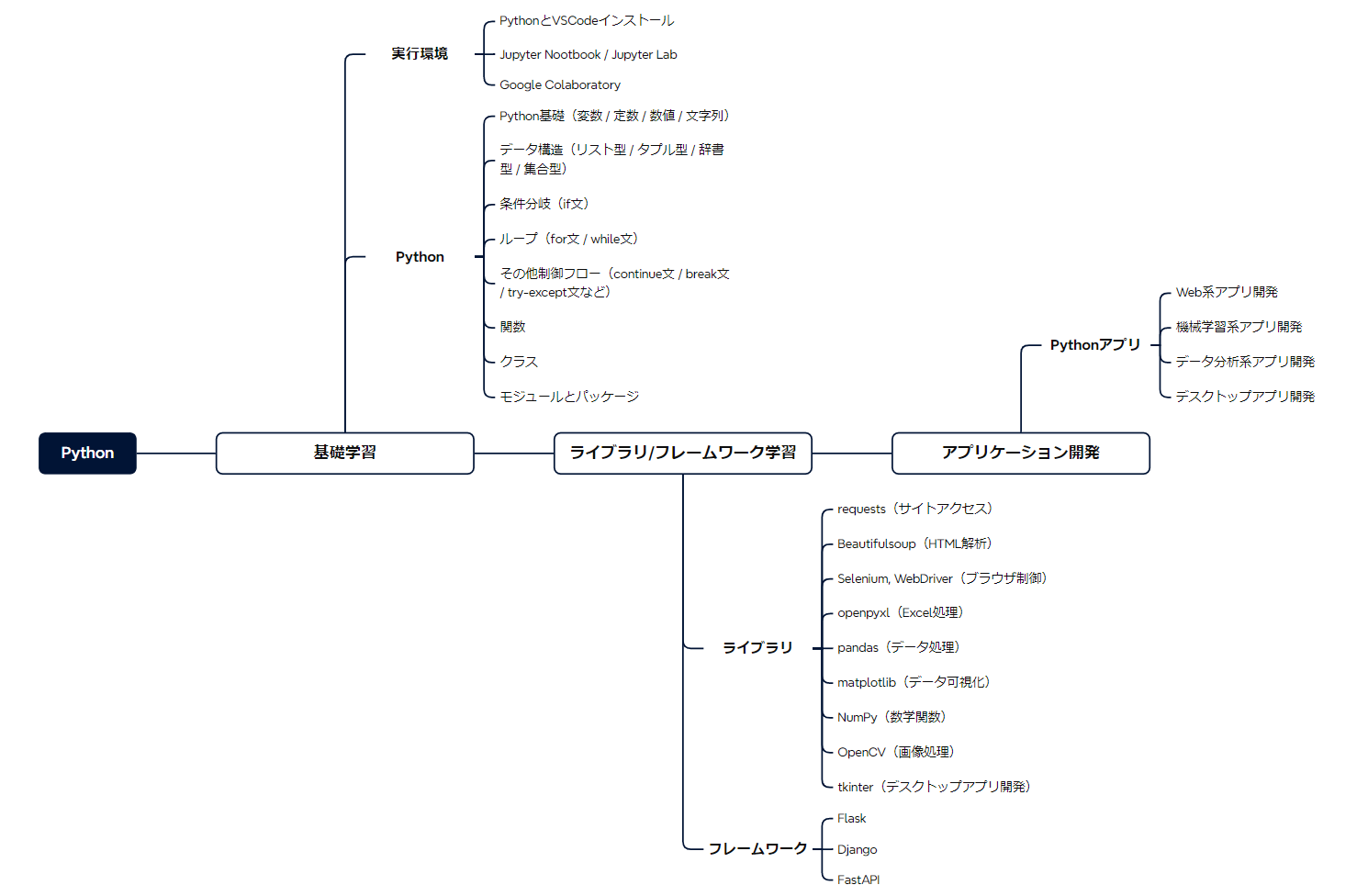
また、Python学習ロードマップで示した通り、学習の順番を間違えないよう注意しましょう。
開発環境構築からアプリ開発に至るまでの学習手順や無料サイト・無料教材情報を知りたい人は「【完全無料】Python学習ロードマップ|初心者向け教材と学習手順」を一読ください。
Python無料教材で完結する学習ロードマップ【初心者完全版】
本記事をお読み頂いているプログラミング初学者向けに、本サイトはPythonを始めるためのガイドを配布しています。
以下に無料配布するPython資料をご紹介します。
- Python入門ガイド
- Python製デスクトップ用GUIライブラリガイド
- Python用学習ロードマップシート
- Tkinter製テンプレート集
- DXアイデア100選スライド
- Python関連のメルマガ情報
- 定期アンケートによる教材強化
これからPython学習を始めたい人へ、Pythonを学ぶメリットや学習ロードマップ用シートを用意しています。



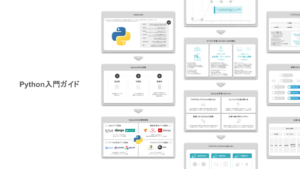
Python入門ガイドの概要

Python入門ガイドは、Python初学者向けに市場の動向や今後のプログラミングのヒントをまとめた資料になります。
以下は、Python入門ガイドの目次になります。(大枠のみ記載)
- Pythonとは
- Pythonの動向
- Pythonを学習するメリット
- Pythonからプログラミングを始める
上記の目次から、Pythonの特徴/開発領域/ビジネス市場の動向/仕事幅の増やし方など様々な観点で図解化しています。
Python製デスクトップ用GUIライブラリガイドの概要

本ガイドは、Pythonでデスクトップアプリを開発する際の基本的な概念から解説した資料になります。
特に、標準ライブラリであるtkinter、拡張版であるttk、モダンなデザインを可能にするttkbootstrapの比較と活用方法までを体系的にまとめたガイドです。
以下は、Python製デスクトップ用GUIライブラリガイドの目次になります。(大枠のみ記載)
- ライブラリとフレームワークの基礎
- GUIライブラリの比較(tkinter / ttk / ttkbootstrap)
- 実装の基本:配置とウィジェット
- ttkbootstrapのテーマデザイン
Pythonで「実用的で見た目の良いツール」を作りたい方にとってのロードマップになっています。
DXアイデア100選スライドの概要

本ガイドは、Pythonを活用して「誰でもできる作業」を自動化する具体的なアイデアをまとめた資料になります。
以下は、DXアイデア100選スライドの目次になります。(大枠のみ記載)
- 導入:賢い働き方へのシフト
- 実務に直結する自動化アイデア集
– Excel・ドキュメント作成|20選
– Web情報収集・リサーチ|20選
– コミュニケーション・通知|20選
– ブラウザ操作・システム連携|20選
– デスクトップアプリ・AIツール活用|20選 - 付加価値の創出
単なる技術解説ではなく「人生をどうハックするか」といった視点で、業務効率化による時間創出のヒントになるアイデア集になります 。
限られた時間を情報収集に極力かけず、他言語よりも「なぜ今Pythonを選ぶべきか」をガイドにしています。
プログラミングにおいて、情報収集の時間短縮は学習時間の短縮に直結します。
開発環境→基礎学習→ライブラリ/FW→アプリ開発に至る学習シートを配布しています。
また、定期アンケートによって「リアルな声」を反映して常に教材改善のアップデート情報を受け取れます。
\ メルアドのみで今すぐ受け取れます /
Jupyter Notebookとは?
Jupyter Notebook(ジュピターノートブック)は、ブラウザ上で動作するGUIベースの対話型実行環境です。
主にデータ分析/データ可視化やAI/機械学習といった数学的な利用に用いられます。
Jupyter Notebookは、以下の分野や職種の方々に利用されています。
- 研究開発におけるデータサイエンティスト
- マーケティング分野におけるデータアナリスト
- 大学機関などのアカデミック分野
また、Jupyter Notebookは以下の特徴があります。
- ローカルサーバーによる実行環境
- データ分析の可視化がインタラクティブ(対話型)
- セル単位による逐次コード実行可能
Jupyter Notebookはローカルサーバー上に実行環境を起動することで、インタラクティブ(対話型)な実行が可能であり、プログラムコードの実行結果が即座に確認できます。
Jupyter NotebookとJupyter Labの違い
Jupyter Notebookのほかに、Jupyter Notebookの後継機として開発されたJupyter Labがあります。
基本的に、Jupyter LabはNotebookの後継機として開発されているため、Notebookが持つ機能より高機能になっています。
- 複数画面による開発が可能
- 目次の拡張とビジュアルデバッカーの機能が同梱
- セルのドラッグ&ドロップ
- マークダウンファイルが記述しやすい
特に、Jupyter Notebookの環境では開発画面をブラウザ上のタブによって実現していましたが、検索タブや別タブによる開発画面によって面倒なタブ切り替えが発生していました。
Jupyter Labでは複数の開発画面を実現しているため、非常に利便性が高まっています。
また、Jupyter Labはセルの入れ替えをドラッグ&ドロップできます。
Jupyter NotebookではなくJupyter Labを詳しく知りたい人は「【Python】Jupyter Labとは?インストールや使い方など開発環境構築まで解説!」を一読ください。
Jupyter Notebookのインストール方法
Jupyter Notebook(ジュピターノートブック)は、主に以下の方法でインストールできます。
Macではターミナル、Windowsではコマンドプロンプトを使用してインストールします。
- Anaconda(Pythonパッケージ)の一括インストール
- Jupyter Notebook単体のインストール
また、全く環境構築ができていない場合を考え、以下の構築ステップを記載します。
Pythonの公式サイトからインストーラーをダウンロードします。
各OSに合わせたインストーラーを起動することでPythonを自身のPCにインストールできます。
Pythonの詳細なインストール手順や設定を画像で知りたい人は「【Python】ダウンロードとインストール方法から開発環境構築まで解説!」を一読ください。
基本的に、Pythonをインストールした時点で付属モジュールとしてpipもインストールしています。
pipモジュールを利用することでJupyter Notebookのインストールが可能になります。
pip --version上記のコードにて、pipモジュールのバージョンを確認できます。
Jupyter Notebookをインストールする場合は、以下のコマンドをターミナルあるいはコマンドプロンプトで実行します。
Pythonパッケージ管理ツールpipを利用することでインストールできます。
pip install jupyterJupyter Notebookを仮想環境に切り替えたい
Jupyter Notebookでデータ分析あるいは開発を実施する際、プロジェクトごとに専用の実行環境を作成し切り替えたいケースがあります。
プロジェクト管理がしやすいことやインストールする各ライブラリ/モジュールの干渉を防ぎエラーを発生させない意図があります。
また、このような開発/分析用として一時的に作成する実行環境を「仮想環境」と呼びます。
ローカル環境で開発/分析を進めるにあたり、venvモジュールを利用した仮想環境を構築します。
venvは、Pythonに標準搭載された仮想環境用モジュールです。
venvを利用することで、プロジェクトごとに分離したPython実行環境を構築できるため、各実行環境でそれぞれのパッケージを管理できます。
- venvによる仮想環境構築方法
- 仮想環境の切り替え方法
上記を含めてJupyter Notebookの仮想環境を構築していきます。
Jupyter Notebookの仮想環境を構築する(Windows)
仮想環境を構築するには、任意のディレクトリで以下のコマンドを実行します。
はじめに、WindowsではPowerShellを起動させ、作業ディレクトリを作成します。
mkdir jupyter-notebook-projectここでは、ディレクトリ名として「jupyter-notebook-project」にしています。
次に、任意のディレクトリに移動します。
cd jupyter-notebook-project任意のディレクトリに移動したら、以下のコマンドを実行しポリシーを変更します。
Set-ExcutionPolicy RemoteSigned CurrentUserまた、変更できたか確認したい場合は以下のコマンドで表示できます。
Get-ExecutionPolicy -Scope CurrentUser応答で「RemoteSigned」が表示されれば変更完了です。
次に、以下のコマンドで仮想環境を作成します。
py -m venv venv仮想環境の切り替え方法
Pythonのvenvモジュールのコマンドは、以下の構成になっています。
py -m venv <仮想環境パス>そのため、「仮想環境パス」に記載したパスに対して仮想環境が作成されます。(上記ではvenvといった仮想環境パス)
作成した仮想環境パスを有効化する際、以下のコマンドを実行します。
.\<仮想環境パス>\Scripts\activate上記のコマンドに記載がある<仮想環境パス>を作成したパスに切り替えて実行することで、各仮想環境を切り替えることができます。
作成した仮想環境venvを有効化します。
.\venv\Scripts\activateここでは、Jupyter Notebookによる実行環境を作成していきます。
pip install jupyter作成した仮想環境にインストールされたパッケージを確認する場合は、以下のコマンドを実行しましょう。
pip listPythonによる仮想環境を構築でき任意のディレクトリのみJupyter Notebookをインストールできた状態になります。
上記のように、特定のディレクトリでJupyter Notebookによる開発/分析が可能になりました。
Jupyter Notebookの起動方法
Jupyter Notebookを起動するには、以下のコードをMacであればターミナル、Windowsであればコマンドプロンプトにて実行します。
jupyter notebookコードを実行すると、http://localhost:8888/treeにアクセスしてJupyter Notebookが起動します。
実際にJupyter Notebookを起動した表示画面が以下になります。
GUI操作によるブラウザ実行環境であるため、プログラミング初心者でも分かりやすい設計になっています。
Jupyter Notebookが起動しない場合の対処
Jupyter Notebookの実行環境を構築する際、AnacondaにてJupyter Notebookをインストールすると起動しないケースがあるようです。
Jupyter Notebookが起動しない場合の対処として、以下の4つを確認するとよいです。
- Internet Explorerのブラウザ使用
- バックグラウンドによる起動はできているがブラウザが開かない
- ネットワークによるセキュリティ制限
- インストール時のAnacondaに欠損ファイルがある
公式ドキュメントに記載されていますが、サポートするブラウザはFirefox/Chrome/Safariの最新バージョンのため確認しておきましょう。
バックグラウンドによる起動ができており、ブラウザが開かない場合は一度http://localhost:8888/treeを手動でアドレスバーに入力してみましょう。
ネットワークによるセキュリティ制限の場合は、導入しているセキュリティソフト等のファイアウォール設定にて、Pythonがサーバーを動作させる際の禁止設定がないか確認しましょう。
パッケージ管理ツールなどの組み合わせでAnacondaを導入した場合、欠損ファイルが発生する可能性もあるため、Anacondaの再インストールを試みましょう。
Jupyter Notebookの日本語化
はじめにJupyter Notebook(ジュピターノートブック)の日本語化を設定しておくと、プログラミング初心者は利用しやすいです。
そのため、ここではJupyter Notebook(ジュピターノートブック)の日本語化の設定を解説します。
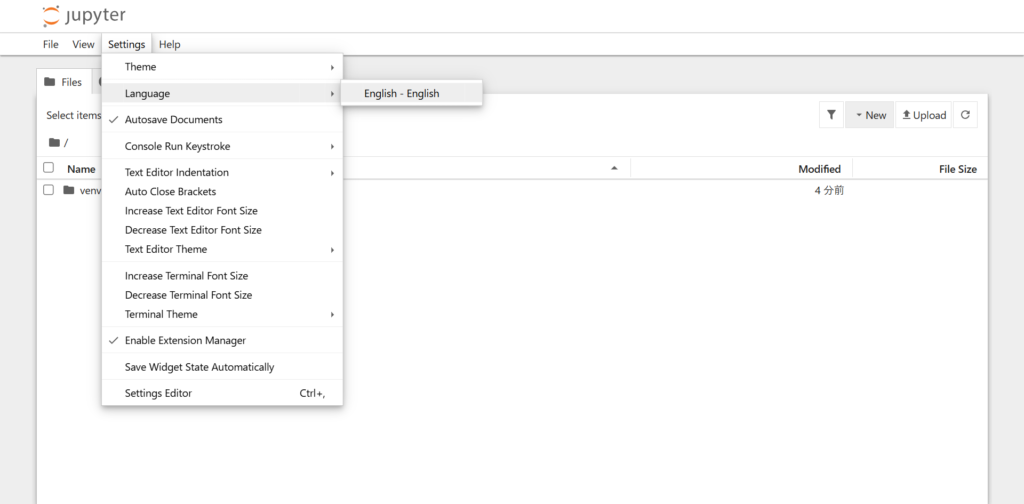
上記の画像は、Jupyter Notebook(ジュピターノートブック)日本語化パッケージをインストールする前であるため、「English」にチェックが入っています。
Macであればターミナル、Windowsであればコマンドプロンプトを起動し、pipでJupyter Notebook(ジュピターノートブック)日本語化パッケージをインストールします。
以下のpipコマンドをターミナルあるいはコマンドプロンプトにて実行してください。
pip install jupyterlab-language-pack-ja-JPJupyter Notebook(ジュピターノートブック)日本語化パッケージのインストール後、Jupyter Notebookを起動すると言語選択が可能になります。
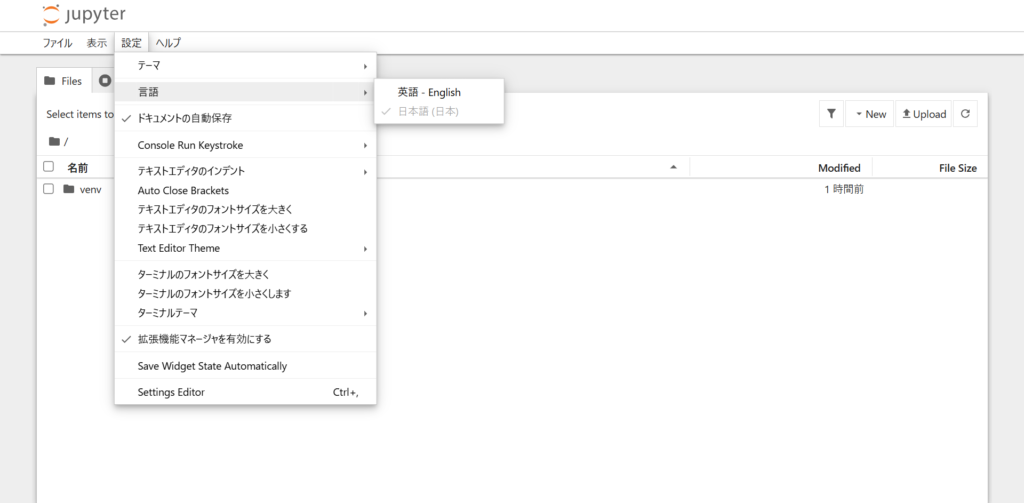
これでJupyter Notebookの日本語化設定は完了です。
Jupyter Notebookの使い方
ここでは、Jupyter Notebookの基本的な使い方としていくつか利用例を解説します。
- Jupyter Notebookにおけるセルの使い方
- Markdown(マークダウン)の使い方
- ファイル名変更とファイル保存
- Jupyter Notebookのファイル共有
- Jupyter Notebookの.ipynbファイルをpythonファイルに変換
- Jupyter Notebookの終了方法
起動時の画面から、順を追って解説していきます。
ここでは、はじめに新規ファイル作成の手順を記載しています。
以下のコマンドをターミナルあるいはコマンドプロンプトにて実行し、Jupyter Notebookをブラウザ上で起動します。
jupyter notebook起動すると、以下の画面が表示されます。
画面の左側には、フォルダ・ファイルの一覧が表示されています。
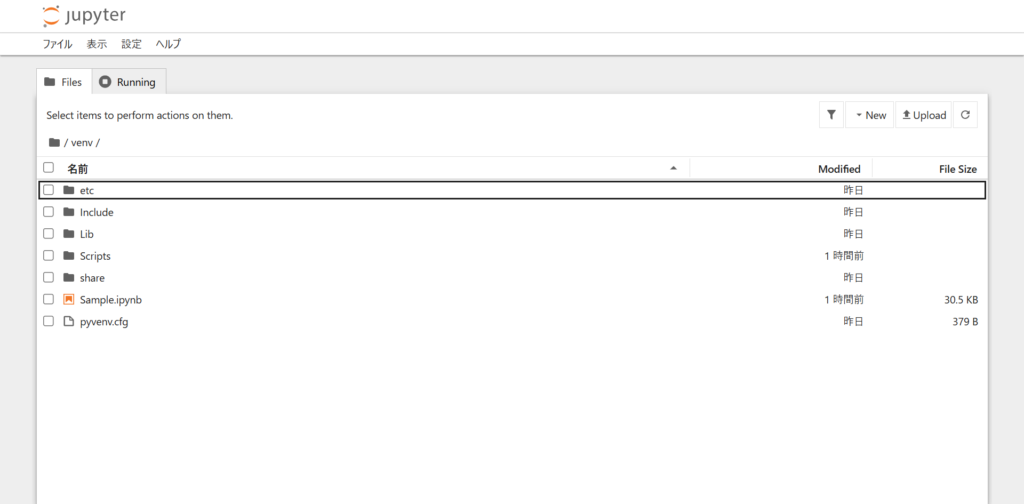
この一覧の中のフォルダの階層から、作業を実施するフォルダを選択してください。
ここでは、仮想環境フォルダである「venv」を例に進めています。
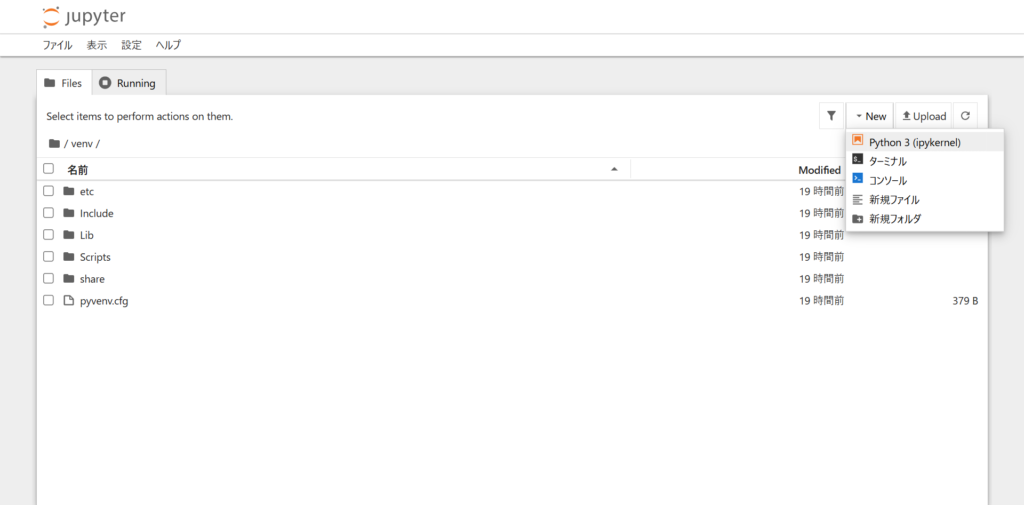
作業するフォルダを選択した後、右側の「New」メニューより「Python3」を選択してください。
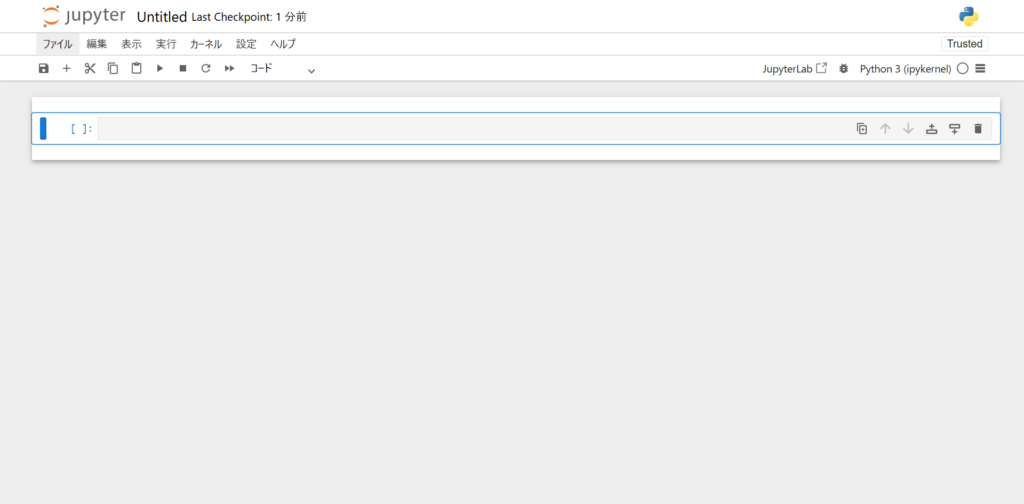
選択するとブラウザ上に新しいタブが作成され、上記のような画面が表示されます。
画面の中に青枠で囲まれた領域を「セル」と言い、この中にプログラムを記述していきます。
セルの左端には[n]と表示されており、nは実行時に連番が表示されます。
試しに、セル内にコードを記述し実行してみましょう。(実行ショートカットキー:Shift + Enter)
Jupyter Notebookにおけるセルの使い方
Jupyter Notebookにおける基本的なセルの使い方を理解しておくと、UI操作が扱いやすくなります。
ここでは、以下の基本的なセルの使い方を解説します。
- セルをたたむ
- セルの分割
- セルの停止
- セルの復元
それぞれのセルの使い方を確認しておきましょう。
セルをたたむ
ここでは、Jupyter Notebookにおいてセルをたたむ操作を実行します。
上述で利用したセルを改めて確認してみます。
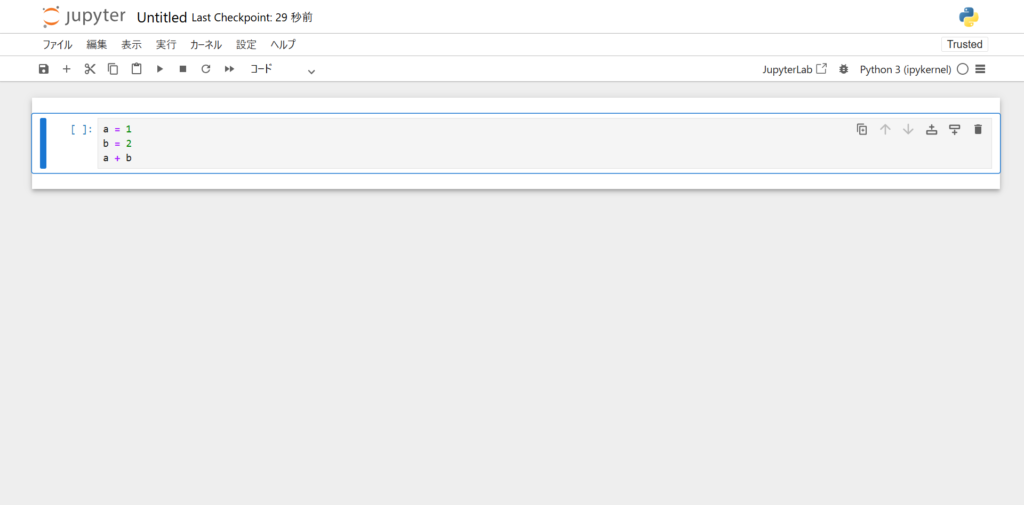
画像を確認すると、セルの左側に青色の縦棒が存在します。
縦棒にカーソルを合わせクリックすると、記述したプログラムの1行目以外が省略されセルをたたむことができます。
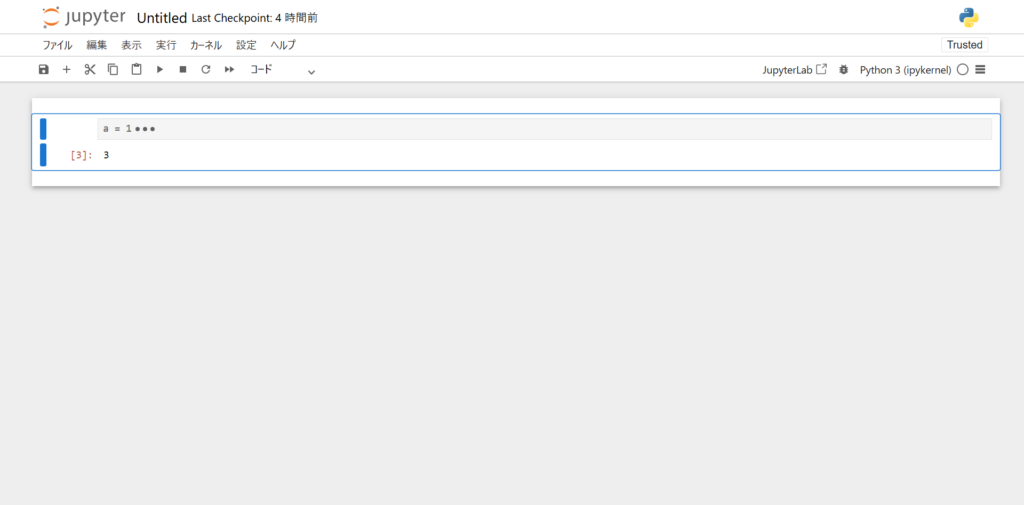
また、コード記述ができる状態にし、上部タブにある「表示」から「選択したコード折りたたむ」を選択してもセルをたたむことができます。
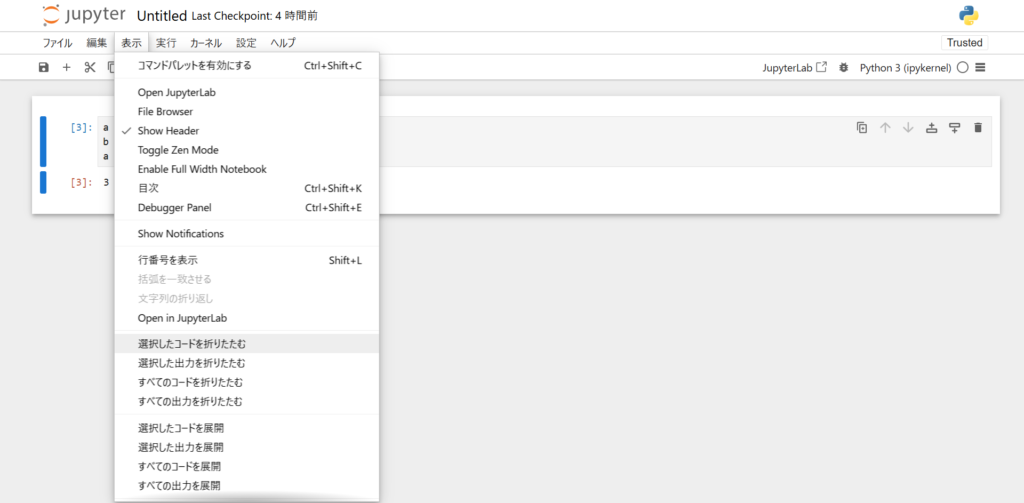
同じく「表示」から「選択したコードを展開」を選択すれば元のコードが展開されます。
セルの分割
次に、Jupyter Notebookにおけるセルの分割を実行します。

上記のセル内のコードにてカーソルを3行目の先頭に位置づけます。
上部タブの「編集」から「セルの分割」を選択すると、分けたいコードが別々のセルに分割されます。
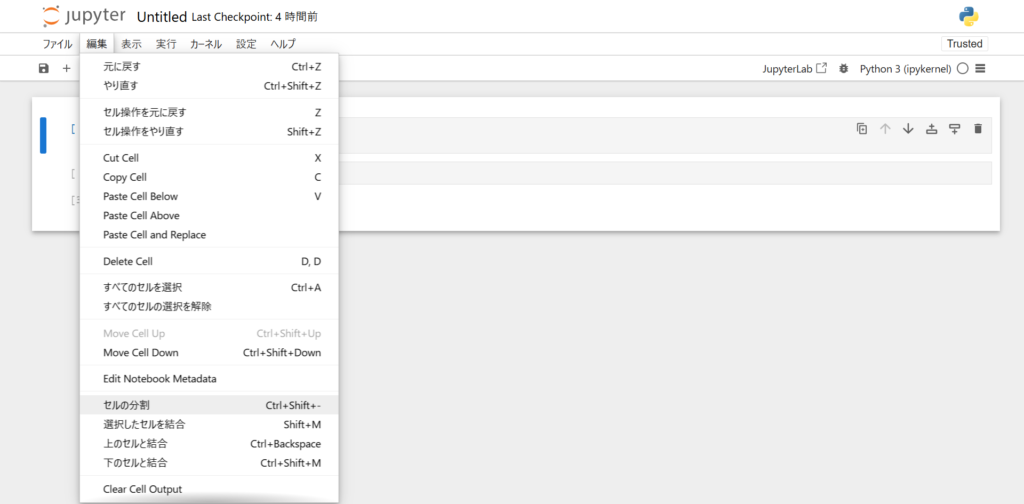
また、セルの分割はショートカットキー「Shift + Ctrl + Minus(-)」でも実行できます。
セルの停止
セルの停止方法はシンプルです。
実行中のセルを手動で停止するには、[カーネル] > [中断] をクリックします。
または、ツールバーにある四角形の停止ボタンをクリックします。
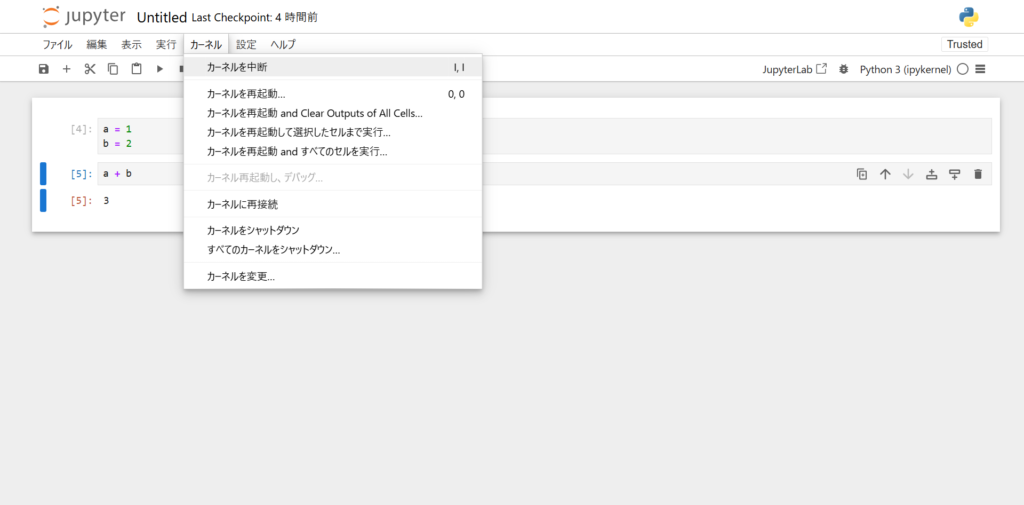
セルの復元
あまりJupyter Notebookに慣れていない人であれば、思わぬ挙動が起きた際に注意が必要です。
ここでは、念のためセルの復元方法も簡潔に解説しておきます。
もしもセルを削除してしまい、元に戻したい場合に「編集」から「元に戻す」をクリックするとセルを復元することができます。
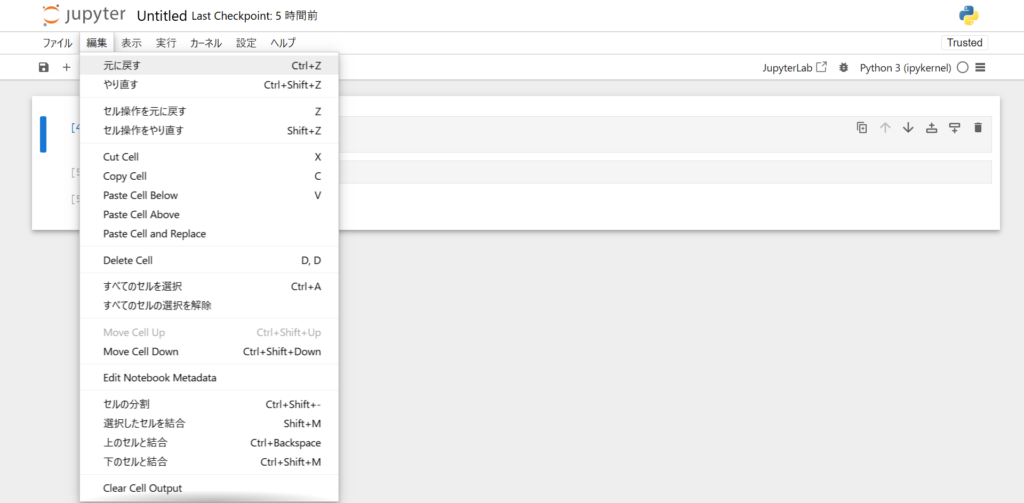
また、セルの復元はショートカットキー「Ctrl + Z」でも実行できます。
Markdown(マークダウン)の使い方
次にJupyter NotebookにおけるMarkdown(マークダウン)の使い方を解説します。
Jupyter Notebookでは、Markdown(マークダウン)と呼ばれる文章を記述でき、コードや実行結果含めた技術的なドキュメント作成や共有に役立てることもできます。
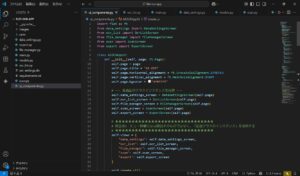
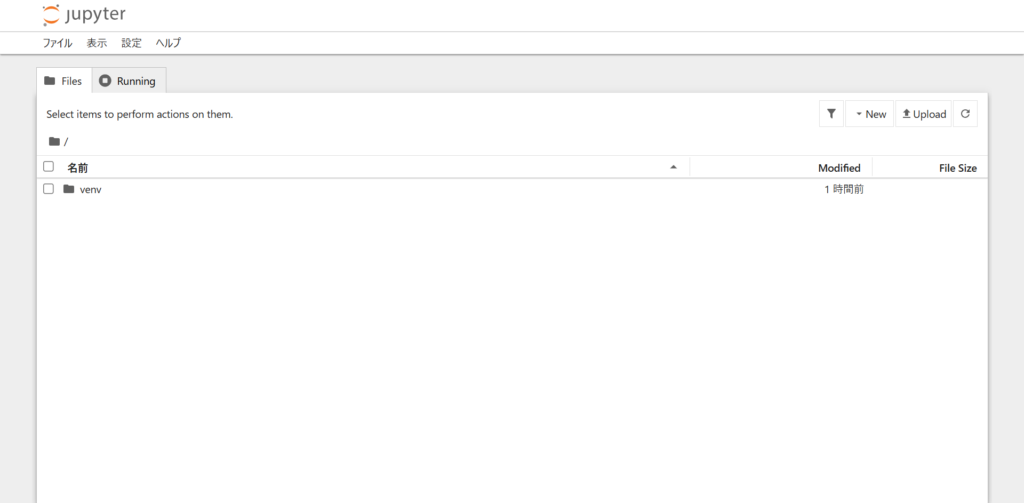
ここでは、試しにダミーデータを利用したデータ分析&プロット表示に関するプログラムコードを記述して実行してみます。
ダミーデータを利用したデータ分析&プロット表示に関するプログラムコード
ダミーデータと分析等で利用するライブラリをインストールします。
pip install numpy scikit-learn matplotlibimport numpy as np
import matplotlib.pyplot as plt
from sklearn.linear_model import LinearRegression
from sklearn.model_selection import train_test_split
from sklearn.metrics import mean_squared_error, r2_score
# ダミーデータの生成
np.random.seed(0)
X = 2 * np.random.rand(100, 1)
y = 4 + 3 * X + np.random.randn(100, 1)
# データをトレーニングセットとテストセットに分割
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 線形回帰モデルの作成とトレーニング
model = LinearRegression()
model.fit(X_train, y_train)
# モデルを用いて予測
y_pred = model.predict(X_test)
# モデルの評価
mse = mean_squared_error(y_test, y_pred)
r2 = r2_score(y_test, y_pred)
print("Mean Squared Error:", mse)
print("R^2 Score:", r2)
# 結果のプロット
plt.scatter(X, y, color='blue', label='Data points')
plt.plot(X_test, y_pred, color='red', linewidth=2, label='Regression line')
plt.xlabel('X')
plt.ylabel('y')
plt.legend()
plt.show()
次に、コードセルの一番上にマークダウン用セルを作成します。
作成したセルを選択した状態で、上部にある「セルタイプ」を選択します。
マークダウン記法とは
Markdown記法とは、テキストを構造的に記述する「マークアップ言語」の一つです。
特定の記号を使って段落や見出し、装飾などを自動的に表示できます。
内容と構造を分けて扱えばよいため、見出しや本文/箇条書きといったレイアウトを気にせず素早く文章を入力できます。
タグを使ってテキストやリンクの構造を指定するHTMLやXMLもマークアップ言語になります。
簡単にマークダウン記法を用いてプログラムの概要と各コード解説、コードの実用例まで記載しました。
また、上部タブの「表示」から「目次」を選択することで左側にマークダウン記法で記載した内容が反映された目次も確認できます。
ファイル名変更とファイル保存
次に、ファイル名の変更と保存方法について解説します。
ファイル名の変更についてはいくつか方法があります。
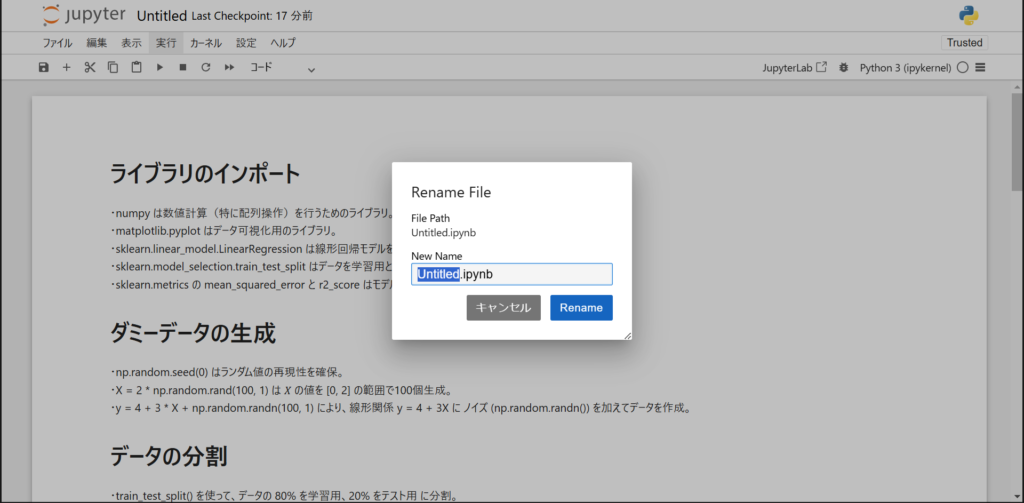
最上部にあるファイル名をクリックすることで、ファイル名の変更を実施できます。
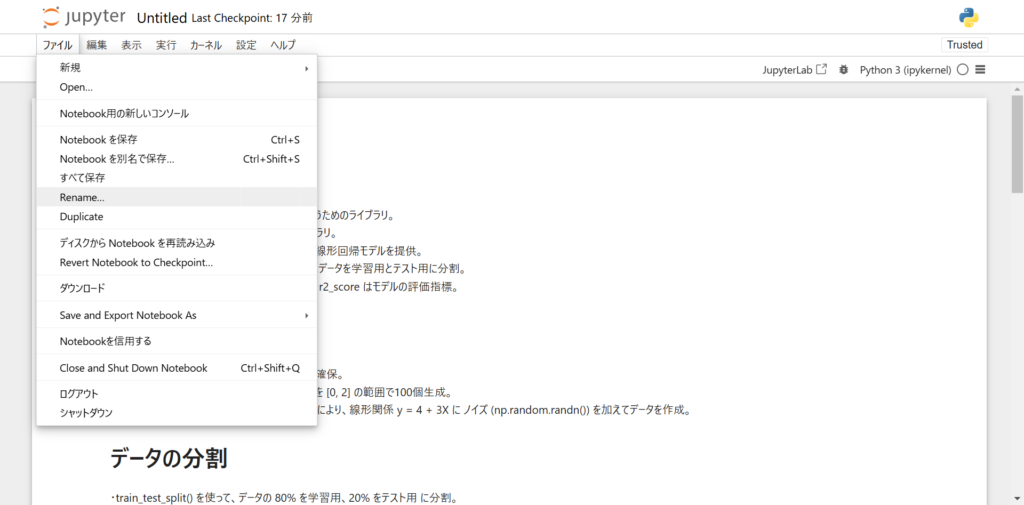
また、上部タブの「ファイル」から「Rename」を選択することでもファイル名変更できます。
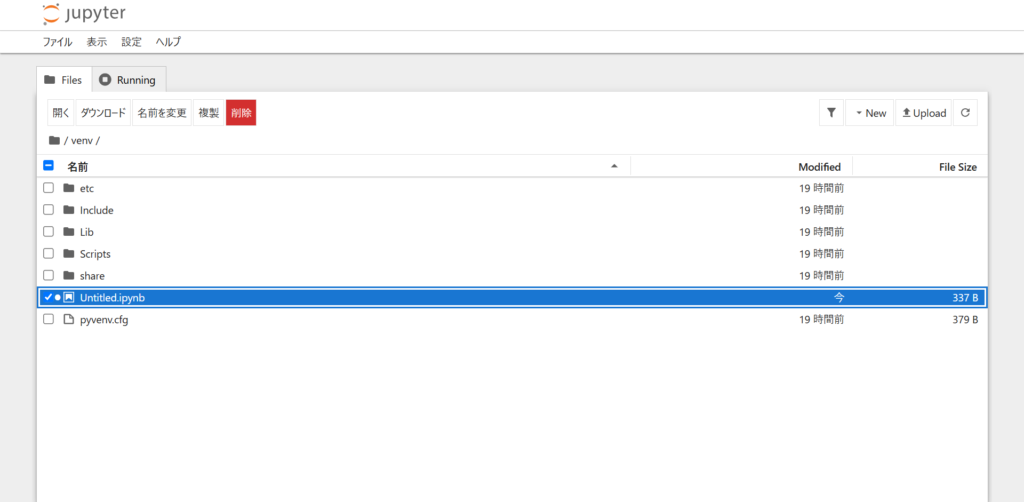
起動画面時に表示されていたtree画面でも、ファイル名変更が可能です。
次に、ファイルの保存方法ですが、非常に簡単です。
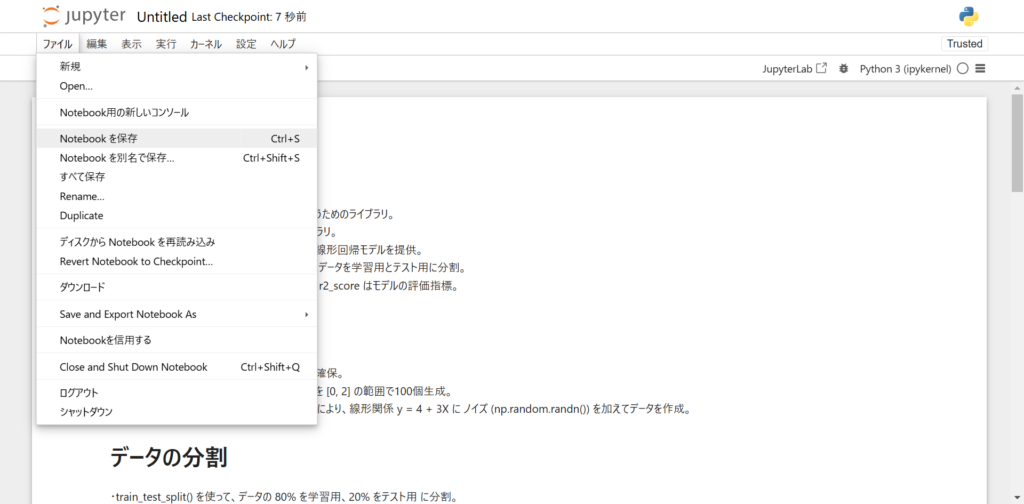
上部タブの「ファイル」から「Notebookを保存」を選択することでファイル保存できます。
また、Jupyter Notebookのショートカットキー「Ctrl + S」でもファイル保存できます。
Jupyter Notebookのファイル共有
Jupyter Notebookは、「.ipynb」といった独自形式の拡張子でファイルをダウンロード/アップロードすることができます。
ここでは、以下の機能を確認します。
- .ipynbファイルのダウンロード
- .ipynbファイルのアップロード
ファイルを共有することでプログラムを別のJupyter Notebook環境へアップロードして実行結果を確認したり、プログラムをダウンロードして配布して他者がプログラムや実行結果を確認することが簡単にできます。
.ipynbファイルのダウンロード
ファイルのダウンロードは、起動画面時にファイル選択を行い左上にある「ダウンロード」をクリックするとダウンロードできます。
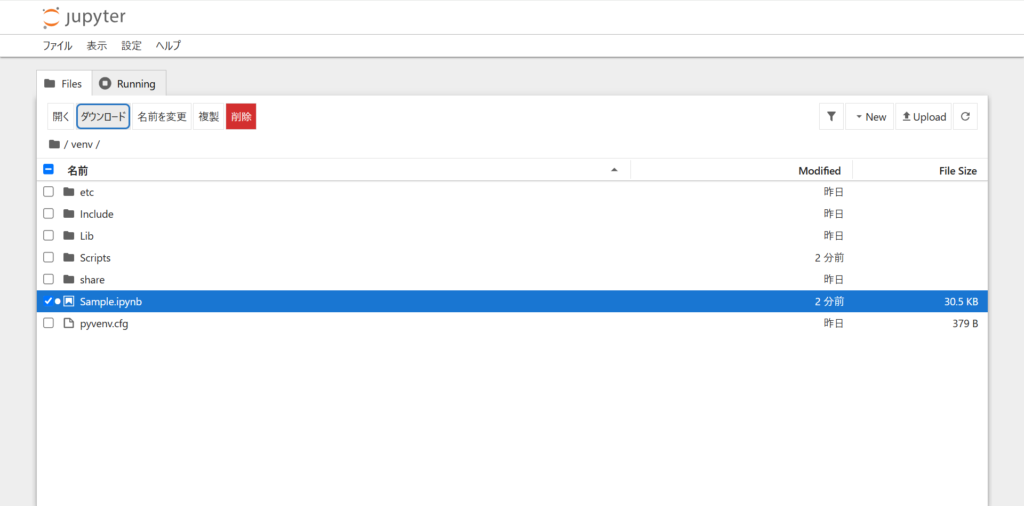
.ipynbファイルのアップロード
ファイルのアップロードは、起動画面時に右上にある「Upload」をクリックするとファイル選択画面に移行するため、上げたいファイルを選択しアップロードできます。
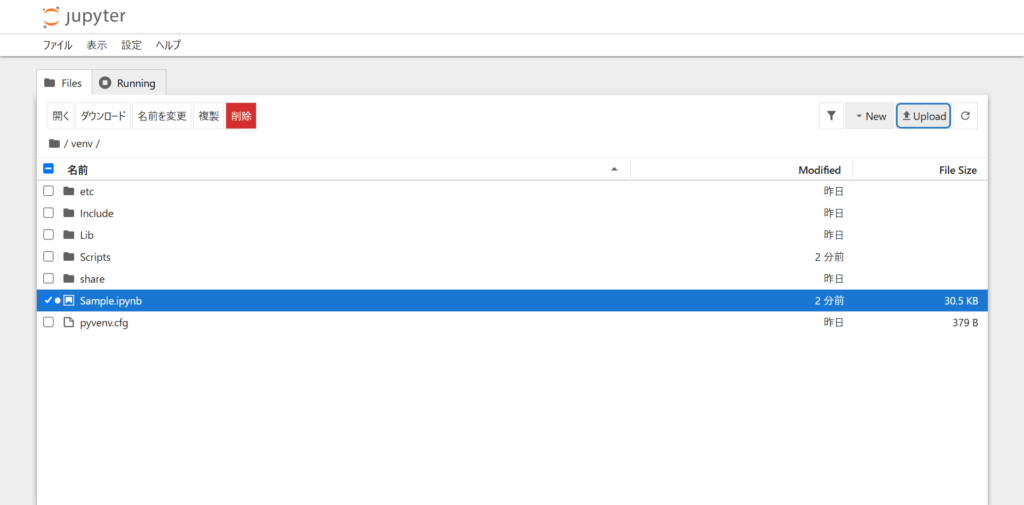
Jupyter Notebookの.ipynbファイルをpythonファイルに変換
Jupyter Notebookは、独自形式の拡張子である「.ipynb」を採用しているため、Pythonファイルである「.py」で利用することができません。
ここでは、直接Jupyter NotebookからPythonファイルの拡張子である「.py」ファイルとしてダウンロードする方法を解説します。
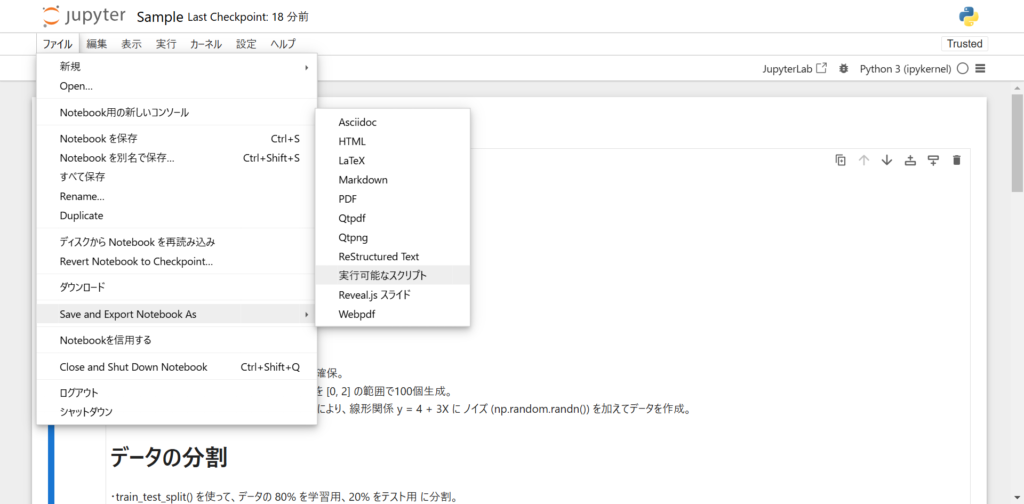
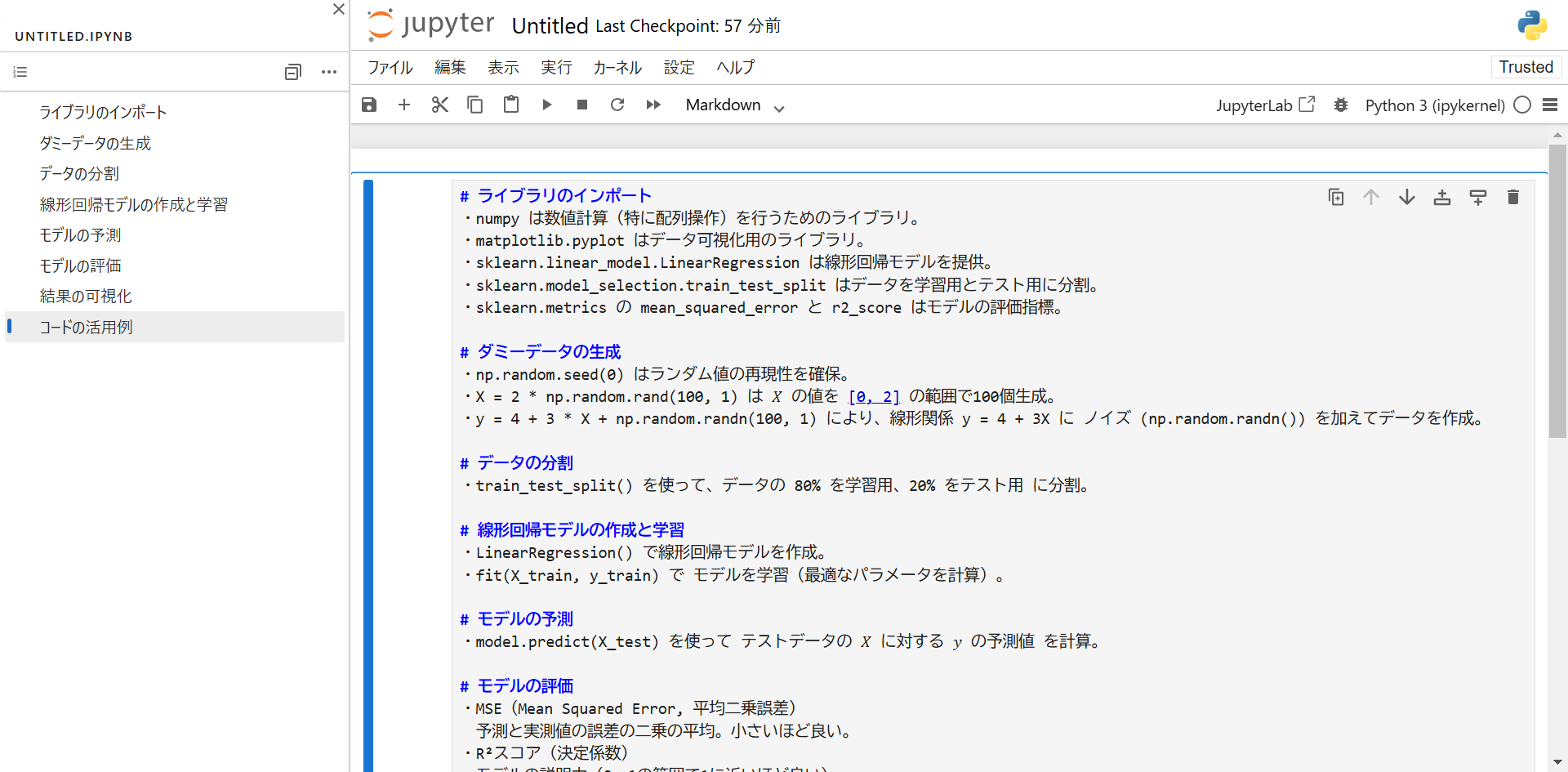
上記画像のように、上部タブの「ファイル」から「Save and Export Notebook as」にカーソルを合わせ、「実行可能なスクリプト」をクリックすると.pyファイルをダウンロードできます。
ダウンロードしたPythonファイル
#!/usr/bin/env python
# coding: utf-8
# # ライブラリのインポート
# ・numpy は数値計算(特に配列操作)を行うためのライブラリ。
# ・matplotlib.pyplot はデータ可視化用のライブラリ。
# ・sklearn.linear_model.LinearRegression は線形回帰モデルを提供。
# ・sklearn.model_selection.train_test_split はデータを学習用とテスト用に分割。
# ・sklearn.metrics の mean_squared_error と r2_score はモデルの評価指標。
#
# # ダミーデータの生成
# ・np.random.seed(0) はランダム値の再現性を確保。
# ・X = 2 * np.random.rand(100, 1) は 𝑋 の値を [0, 2] の範囲で100個生成。
# ・y = 4 + 3 * X + np.random.randn(100, 1) により、線形関係 y = 4 + 3X に ノイズ (np.random.randn()) を加えてデータを作成。
#
# # データの分割
# ・train_test_split() を使って、データの 80% を学習用、20% をテスト用 に分割。
#
# # 線形回帰モデルの作成と学習
# ・LinearRegression() で線形回帰モデルを作成。
# ・fit(X_train, y_train) で モデルを学習(最適なパラメータを計算)。
#
# # モデルの予測
# ・model.predict(X_test) を使って テストデータの 𝑋 に対する 𝑦 の予測値 を計算。
#
# # モデルの評価
# ・MSE(Mean Squared Error, 平均二乗誤差)
# 予測と実測値の誤差の二乗の平均。小さいほど良い。
# ・R²スコア(決定係数)
# モデルの説明力(0〜1の範囲で1に近いほど良い)。
#
# # 結果の可視化
# ・データ点(青) を散布図として描画。
# ・予測結果(赤の回帰直線) を描画。
# ・plt.show() でグラフを表示。
#
# # コードの活用例
# 1. 売上予測
# X を 広告費、y を 売上 とすると、広告費が増えたときの売上予測ができる。
# 2. 住宅価格予測
# X を 面積、y を 住宅価格 として、面積が増えた場合の価格の予測が可能。
# 3. 体重とカロリー消費の関係
# X を 運動時間、y を 消費カロリー として、運動時間に応じた消費カロリーを予測。
#
# このように、一つの変数が増えることで別の変数がどう変わるか を分析するのに適した手法です。
# In[4]:
import numpy as np
import matplotlib.pyplot as plt
from sklearn.linear_model import LinearRegression
from sklearn.model_selection import train_test_split
from sklearn.metrics import mean_squared_error, r2_score
# ダミーデータの生成
np.random.seed(0)
X = 2 * np.random.rand(100, 1)
y = 4 + 3 * X + np.random.randn(100, 1)
# データをトレーニングセットとテストセットに分割
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 線形回帰モデルの作成とトレーニング
model = LinearRegression()
model.fit(X_train, y_train)
# モデルを用いて予測
y_pred = model.predict(X_test)
# モデルの評価
mse = mean_squared_error(y_test, y_pred)
r2 = r2_score(y_test, y_pred)
print("Mean Squared Error:", mse)
print("R^2 Score:", r2)
# 結果のプロット
plt.scatter(X, y, color='blue', label='Data points')
plt.plot(X_test, y_pred, color='red', linewidth=2, label='Regression line')
plt.xlabel('X')
plt.ylabel('y')
plt.legend()
plt.show()マークダウン形式による概要もコメントアウトでしっかり出力してくれます。
Jupyter Notebookの終了方法
最後に、Jupyter Notebookの終了方法です。
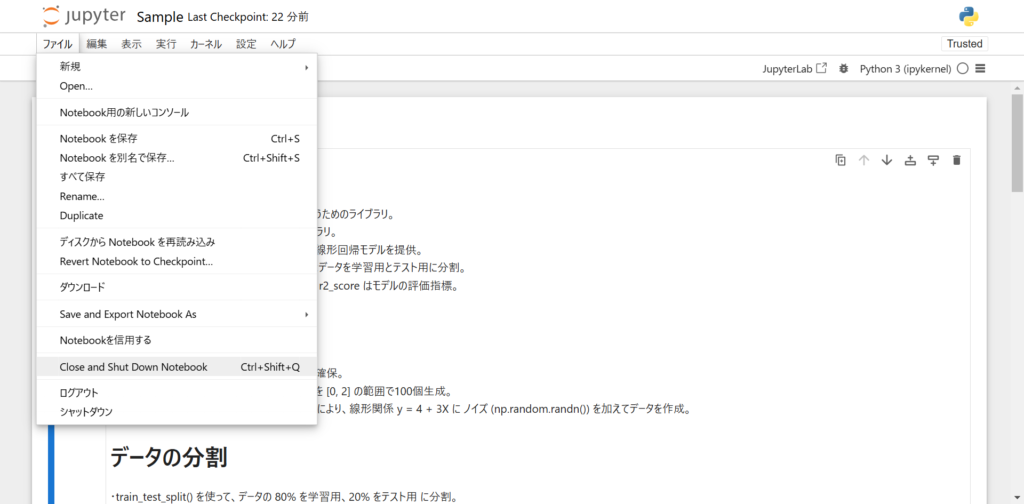
上部タブの「ファイル」から「Close and Shut Down Notebook」をクリックすればJupyter Notebookを終了できます。
Jupyter Notebookの拡張機能のインストール方法
Jupyter Notebookには、拡張機能を追加することができます。
「nbextensions」といった拡張機能ツールをインストールする必要があります。
以下のコマンドをターミナルあるいはコマンドプロンプトにて実行します。
conda install -c conda-forge jupyter_contrib_nbextensions拡張機能の有効化を実行するには、Jupyter Notebookを再起動し「nbextensions」タブから必要な拡張機能を有効化しましょう。
Jupyter Labに生成AI(jupyter-ai)を導入する
「Jupyter AI」とは、Jupyter環境(JupyterLab, Jupyter Notebook)に生成AIを導入することができるパッケージです。
ここでは、Jupyter AIをインストールして生成AIを利用できるJupyter環境を構築します。
Jupyter環境を利用している任意のディレクトリにて、以下のコマンドでJupyter AIをインストールします。
pip install jupyter-ai正しくインストールされたかを確認するため、以下のコマンドでJupyter Labを起動します。
jupyter labサイドバーにチャットアイコンが表示されれば、正しくインストールされています。
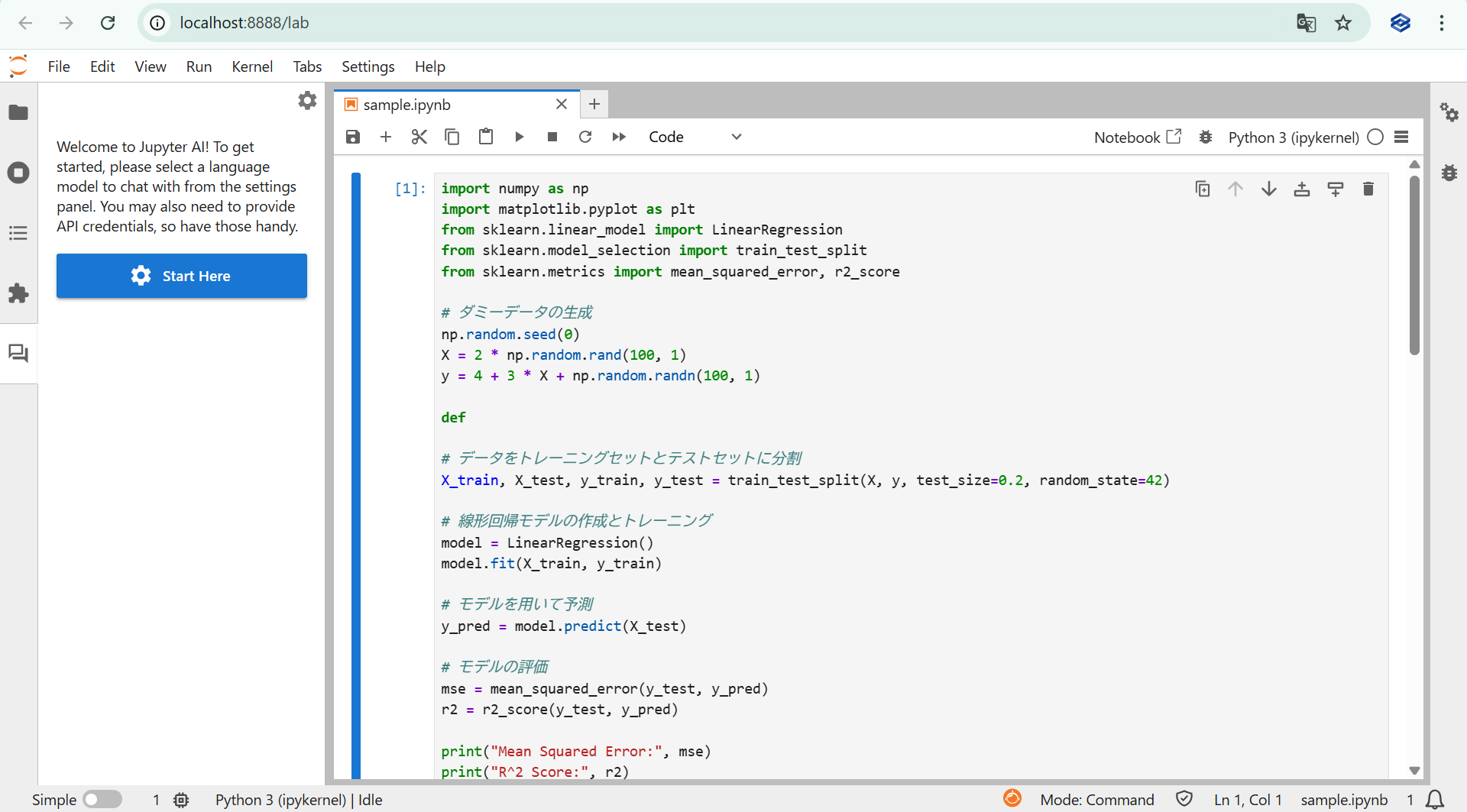
また、以下は英文を翻訳した内容になります。
Jupyter AIへようこそ!まずは設定パネルからチャットする言語モデルを選択してください。
API認証情報の提供が必要になる場合もありますので、ご用意ください。
Jupyter AIの使い方
Jupyter AIには、以下の使い方があります。
- Jupyter AIをサイドバーから使う方法
- Jupyter AIをNotebook内で使う方法
各方法について、事前準備と使い方を解説します。
Jupyter AIをサイドバーから使う方法
サイドバーのチャットアイコンをクリックして、「Start Here」をクリックします。
設定画面は以下になります。
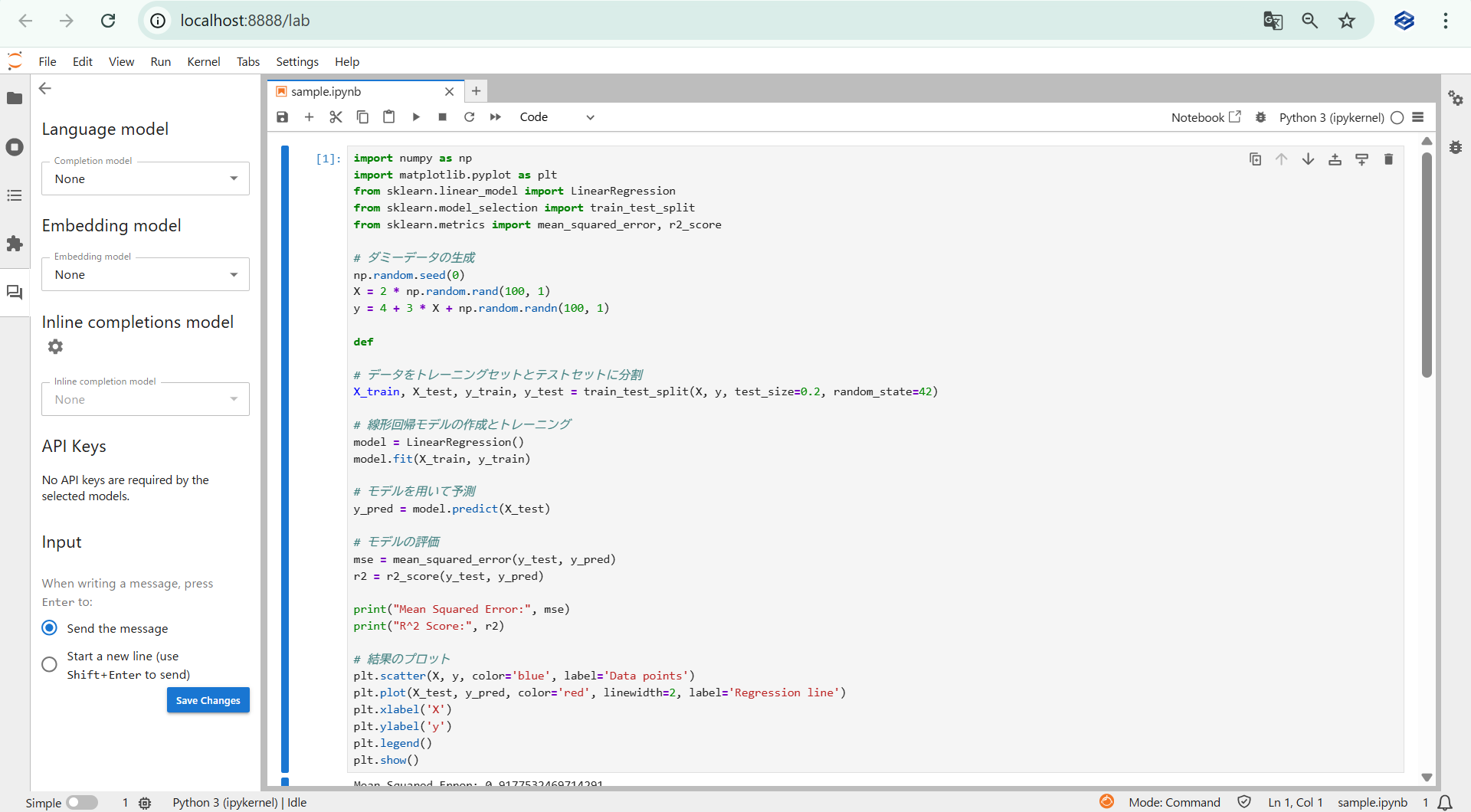
以下はLanguage model(言語モデル)における設定項目欄になります。
- Completion model(補完モデル)
- Embedding model(埋め込みモデル)
- Inline completions model(インライン補完モデル)
- API Keys(モデル選択すると入力欄出現)
基本的には、Completion model(補完モデル)を選択後、API Keyを入力し設定保存すればチャット形式でAIを利用できます。
Jupyter AIをNotebook内で使う方法
次に、Jupyter AIをNotebook内で使う方法になります。
%%aiといったマジックコマンドを使い、chatGPTとメッセージのやり取りを実施できます。
始めに、OPEN_API_KEYを設定します。
そのために、Notebookのセルで以下のコマンドを実行します。
%env OPENAI_API_KEY={your_open_api_key}次に、%%aiマジックコマンドを有効化します。
%load_ext jupyter_ai_magics実際に、%%aiコマンドを使用しJupyter Notebook上でChatGPTとやり取りができます。
以下をセル内に入力することで実行できます。
%%ai chatgpt
ダミーデータを用意し、matplotlibで可視化したグラフを描画するサンプルコードを記述してくださいエラー対処や課題に対する質問などJupyter AIによってコード生成を実施できるため、コード記述の生産性を上げられます。
Jupyter Notebookをオンラインで利用する
Jupyter Notebookを自身のPC上で展開するにあたり、問題が起こるケースもあります。
- 利用するPCのスペックによって動作が遅い
- ローカル環境設定によるエラーで起動できない
様々な問題が個々人のPCによって発生すると推測しますが、Jupyter Notebookをオンラインで活用することも可能です。
以下は、Jupyter Notebookの機能をオンライン上で利用できるサービスになります。
- Google Colaboratory
- Microsoft Azure Notebooks
- Binder
- Kaggle
- PaizaCloud
以下は、各サービスの比較表になります。
| サービス名 | Google Colab | Microsoft Azure Notebooks | Binder | Kaggle | PaizaCloud |
|---|---|---|---|---|---|
| URL | https://colab.research.google.com | https://notebooks.azure.com | https://mybinder.org/ | https://www.kaggle.com | https://paiza.cloud |
| 利用条件 | Googleアカウント | Microsoftアカウント | GitHubアカウント | Kaggleアカウント | Paizaアカウント |
| GPU | 〇(TPUも有り) | ✕ | ✕ | 〇 | ✕ |
| 保存容量 | 15GB | 1GB | 指定なし | 5GB | 1GB |
| 自動オフ | 60分後 | 60分後 | 20分後 | 20分後 | 60分後 |
| プロジェクトリセット | 12時間後 | 8時間後 | 12時間後 | 6時間後 | 24時間後 |
| .ipynbの読み込み | 〇 | 〇 | 〇 | 〇 | 〇 |
筆者のおすすめは、Google ColaboratoryによるJupyter Notebookの活用です。
Googleアカウントがあればすぐにサービス利用ができる他、機械学習に活用されるTensorFlowやKeras/scikit-learnなど機械学習フレームワークやライブラリが既にインストールされています。
また、保存容量が多い点やハイスペックな環境も整備されているなど利点が数多くあります。
Google上の様々なサービスと連携も可能であり、使い勝手が非常に良いです。
Google Colaboratoryによるオンライン上のJupyter Notebookを利用したい人は「【Python】Google Colaboratoryとは?料金から使い方まで網羅的に解説!」を一読ください。
Jupyter Notebookが使いにくい場合
Jupyter Notebookが起動し利用できるが、操作面に対して使いにくい場合があります。
Jupyter Notebookが使いにくい場合、以下を検討してみるのもよいでしょう。
- Jupyter Notebookのショートカットキー活用
- Jupyter Labへの移行
快適な環境を手に入れることで、Jupyter Notebookは使いやすくなっていきます。
Jupyter Notebookのショートカットキー活用
Jupyter Notebookには、上部タブで様々な機能が備えられています。
しかし、それらを毎度カーソルで操作するとかえって時間を取られてしまい、操作性が悪く開発効率が悪化します。
以下は、Jupyter Notebookの代表的なショートカットキーになります。
- 実行:Ctrl + Enter
- セル追加:Shift + Enter
- セル削除:セル選択時「D」2回押下
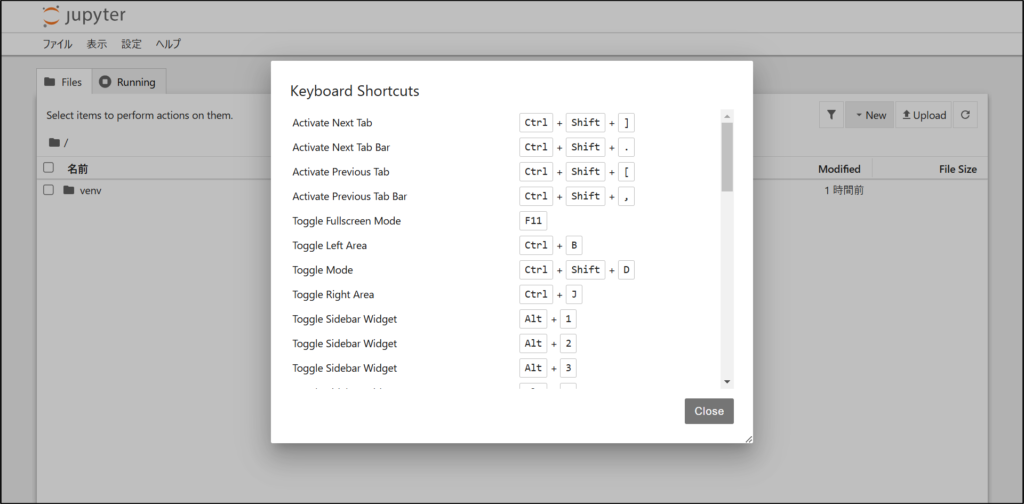
また、画面操作やサイドバー操作など数多くのショートカットキーが存在するので、詳細は以下の画像のように一覧表を確認してください。
「Show Keyboard Shortcuts…」をクリックすると一覧表が確認できます。
Jupyter Labへの移行
ショートカットキーといったJupyter Notebookの操作性だけでなく、以下の使いにくい場面もあると思います。
- 複数画面による開発ができない
- セルの位置変更ができない(最新バージョン改善済)
これらの悩みを解決するものとして、Jupyter Notebookの後継機であるJupyter Labがおすすめです。
Jupyter Labは操作改善や多機能実装が実施され、Jupyter Notebookよりも使いやすい環境になっています。
Jupyter Labのインストールを検討したい人は「【Python】Jupyter Labとは?インストールや使い方など開発環境構築まで解説!」を一読ください。