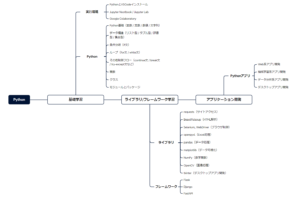
データ処理・データ分析で多用されるPythonライブラリであるpandasについてまとめた記事になります。
- pandasの基本的な使い方を知りたい人
- pandasの便利なメソッドを使いたい人
- データ分析業務で利用するケースも知りたい人
上記の悩みを解決しながら、pandasのインストールから使い方まで解説します。
また、データ処理/分析で便利なメソッドも数多く記載しています。
▼【無料教材】Pythonを学びたい人へ資料を配布中▼
本記事をお読み頂いているプログラミング初学者向けに、本サイトはPythonを始めるためのガイドを配布しています。
以下に無料配布するPython資料をご紹介します。
- Python入門ガイド
- Python製デスクトップ用GUIライブラリガイド
- Python用学習ロードマップシート
- Tkinter製テンプレート集
- DXアイデア100選スライド
限られた時間を情報収集に極力かけず、他言語よりも「なぜ今Pythonを選ぶべきか」をガイドにしています。
プログラミングにおいて、情報収集の時間短縮は学習時間の短縮に直結します。
開発環境→基礎学習→ライブラリ/FW→アプリ開発に至る学習シートを配布しています。
また、定期アンケートによって「リアルな声」を反映して常に教材改善のアップデート情報を受け取れます。
\ メルアドのみで今すぐ受け取れます /
pandasとは

近年、生成AIやAIエージェントに関するプロダクト/サービスが乱立し、機械学習/深層学習を始めデータ処理あるいはデータ分析が重要になっています。
pandasは社内データの整理/分析からAIのモデル精度向上まで、様々なケースのデータ処理で利用されるPythonライブラリです。
以下は、pandasの主な特徴になります。
- 高速でデータ操作するSeries, DataFrameオブジェクト
- データ間で相互に読み書きするためのツール群
- データ統合された際の欠損値処理
- データセットの柔軟な変形およびピボット
- ラベルに基づいたスライスや巨大なデータセットのサブセット取得
- データセットに対する集計および変換
- 高性能なデータセットのマージと結合
- 時系列データの生成
- パフォーマンスのための高度な最適化
様々なデータセットに対する操作/効率化などを実現する特徴があります。
pandasのインストール
pandasを利用するためには、ローカルPC上にインストールする必要があります。
以下は、pandasのインストール方法になります。
- Anaconda(Pythonパッケージ)の一括インストール
- pandas単体のインストール
また、全く環境構築ができていない場合を考え、以下の構築ステップを記載します。
Pythonの公式サイトからインストーラーをダウンロードします。
各OSに合わせたインストーラーを起動することでPythonを自身のPCにインストールできます。
Pythonの詳細なインストール手順や設定を画像で知りたい人は「【Python】ダウンロードとインストール方法から開発環境構築まで解説!」を一読ください。
基本的に、Pythonをインストールした時点で付属モジュールとしてpipもインストールしています。
pipモジュールを利用することでpandasのインストールが可能になります。
pip --version上記のコードにて、pipモジュールのバージョンを確認できます。
pandasをインストールする場合は、以下のコマンドをターミナルあるいはコマンドプロンプトで実行します。
Pythonパッケージ管理ツールpipを利用することでインストールできます。
pip install pandasまた、データ分析環境でよく利用されるJupyter NotebookあるいはJupyter Labの記事も一読ください。
オンライン環境でPythonを扱いたい人は「【Python】Google Colaboratoryとは?料金から使い方まで網羅的に解説!」を一読ください。
pandasの代表的な使い方
pandasの代表的な使い方として、以下のメソッドを利用するケースになると思います。
- pandas|Series
- pandas|DataFrame
pandasライブラリは、Pythonにおけるデータ操作やデータ分析の強力なツールです。
特に、Series(1次元データ)とDataFrame(2次元データ)といった2つの主要なデータ構造を提供しています。
始めにSeriesに焦点を当てて、解説と実行例を示します。
pandas|Seriesの基本的な使い方
pandasにおけるSeriesの基本的な使い方を解説します。
- pandasのインポート方法
- list/dict/様々なデータ型のSeries作成
- Series作成時の名前追加とrename方法(カラム)
- DataFrameの列を抽出しSeriesを作成
- SeriesからDataFrameへの変換
- Seriesからデータの抽出方法(インデックス/条件指定/スライス)
- Seriesへのデータ(要素)の追加/削除/変更
- Seriesのインデックスを利用した演算
- Seriesのソート方法(sort_index/sort_values)
- Seriesの結合方法(concat)
- Seriesから統計情報の取得
- Seriesを使ったデータ分析例
それぞれのメソッドを活用することでデータ操作や加工が簡単に実行できます。
pandasのインポート方法
pandasをインポートすることで、pandasの機能を利用できます。
import pandas as pdpandasのインストール後は、import文によって利用可能になります。
また、asによって変数として省略形を利用していきます。
list/dict/様々なデータ型のSeries作成
ここでは、様々なデータ型によるSeries作成を実施します。
- リストデータからSeries作成
- ディクショナリデータからSeries作成
- 数値/文字列データの要素を持ったSeries作成
リストデータからSeries作成
pd.Series() を使って、リストからSeriesを作成できます。
インデックスを指定しない場合、デフォルトで0から始まる整数インデックスが付与されます。
index引数を使って、カスタムインデックスを設定できます。
# リストからSeriesを作成(デフォルトインデックス)
s1 = pd.Series([10, 20, 30, 40, 50])
print(s1)
'''
出力結果:s1
0 10
1 20
2 30
3 40
4 50
dtype: int64
'''
# インデックスを指定してSeriesを作成
s2 = pd.Series([10, 20, 30], index=['a', 'b', 'c'])
print(s2)
'''
出力結果:s2
a 10
b 20
c 30
dtype: int64
'''ディクショナリデータからSeries作成
dict(辞書型オブジェクト)からもSeries作成可能です。
辞書のキーがSeriesのインデックス、値が要素になります。
# 辞書データからSeriesを作成
data = {'apple': 100, 'banana': 200, 'cherry': 300}
s3 = pd.Series(data)
print(s3)
'''
出力結果:s3
apple 100
banana 200
cherry 300
dtype: int64
'''数値/文字列データの要素を持ったSeries作成
Seriesは数値データ、文字列データ、様々な要素を持ったデータも扱えます。
Seriesは自動的にデータ型を推測してくれます。
# 数値データのSeries
s4 = pd.Series([1, 2, 3, 4, 5])
print(s4)
'''
出力結果:s4
0 1
1 2
2 3
3 4
4 5
dtype: int64
'''
# 文字列データのSeries
s5 = pd.Series(['one', 'two', 'three', 'four'])
print(s5)
'''
出力結果:s5
0 one
1 two
2 three
3 four
dtype: object
'''Series作成時の名前追加とrename方法(カラム)
Seriesに名前(name属性)を付けて、列名として扱うことができます。
また、.rename()メソッドでSeriesの名前を変更可能です。
# Seriesに名前を付ける
s6 = pd.Series([100, 200, 300], name='Sales')
print(s6)
'''
出力結果:s6
0 100
1 200
2 300
Name: Sales, dtype: int64
'''
# Seriesの名前を変更する
s6 = s6.rename('Revenue')
print(s6)
'''
出力結果:s6
0 100
1 200
2 300
Name: Revenue, dtype: int64
'''DataFrameの列を抽出しSeriesを作成
DataFrameにおける特定の列を取得することで、Seriesを生成できます。
df[‘column_name’] の形式で抽出可能です。
# DataFrameからSeriesを取得
df = pd.DataFrame({
'Product': ['A', 'B', 'C'],
'Sales': [100, 200, 300]
})
s7 = df['Sales']
print(s7)
'''
出力結果:s7
0 100
1 200
2 300
Name: Sales, dtype: int64
'''SeriesからDataFrameへの変換
.to_frame()メソッドを使用することで、SeriesをDataFrameに変換可能です。
また、name引数で新しいカラム名を指定できます。
# SeriesをDataFrameに変換
s8 = pd.Series([10, 20, 30], index=['a', 'b', 'c'])
df2 = s8.to_frame(name='Values')
print(df2)
'''
出力結果:df2
Values
a 10
b 20
c 30
'''Seriesからデータの抽出方法(インデックス/条件指定/スライス)
Seriesデータは、インデックス指定/条件指定スライスでデータを抽出できます。
s[‘index’]、s[s > value]、s[start:stop]の形式です。
s9 = pd.Series([100, 200, 300, 400], index=['a', 'b', 'c', 'd'])
# インデックス指定
print(s9['b'])
'''
出力結果:s9
200
'''
# 条件指定
print(s9[s9 > 200])
'''
出力結果:s9
c 300
d 400
dtype: int64
'''
# スライス
print(s9['b':'d'])
'''
出力結果:s9
b 200
c 300
d 400
dtype: int64
'''Seriesへのデータ(要素)の追加/削除/変更
データ要素の追加方法は、Series[インデックス] = 値 で要素を追加できます。
データ要素の削除方法は、.drop(インデックス) を使うことで、特定の要素を削除できます。
データ要素の変更方法は、既存のインデックスに新しい値を代入することで要素を変更できます。
# 初期のSeriesを作成
s = pd.Series([1, 2, 3], index=['a', 'b', 'c'])
print("元のSeries:\n", s)
'''
元のSeries:
a 1
b 2
c 3
dtype: int64
'''
# 要素の追加
s['d'] = 4
print("要素の追加 (d: 4):\n", s)
'''
要素の追加 (d: 4):
a 1
b 2
c 3
d 4
dtype: int64
'''
# 要素の削除
s = s.drop('b')
print("要素の削除 ('b'):\n", s)
'''
要素の削除 ('b'):
a 1
c 3
d 4
dtype: int64
'''
# 要素の変更
s['a'] = 10
print("要素の変更 ('a' → 10):\n", s)
'''
要素の変更 ('a' → 10):
a 10
c 3
d 4
dtype: int64
'''Seriesのインデックスを利用した演算
インデックスが一致する要素同士で自動的に演算を行います。
存在しないインデックス同士の演算結果は NaN(欠損値)になります。
# 2つのSeriesを作成
s1 = pd.Series([1, 2, 3], index=['a', 'b', 'c'])
s2 = pd.Series([10, 20, 30], index=['a', 'b', 'd'])
# インデックスを利用した演算
result = s1 + s2
print("Series同士の演算結果:\n", result)
'''
Series同士の演算結果:
a 11.0
b 22.0
c NaN
d NaN
dtype: float64
'''aとbは通常通り計算されます。
cとdはインデックスが一致しないため、NaN(欠損値)が表示されます。
Seriesのソート方法(sort_index/sort_values)
.sort_index()は、インデックス順にソートします。
.sort_values()は、要素の値順にソートします。
ascending引数を使って昇順/降順を切り替え可能です。
s = pd.Series([10, 30, 20], index=['c', 'a', 'b'])
# インデックスで昇順ソート
print("インデックス順にソート:\n", s.sort_index())
'''
インデックス順にソート:
a 30
b 20
c 10
dtype: int64
'''
# インデックスで降順ソート
print("インデックスを降順にソート:\n", s.sort_index(ascending=False))
'''
インデックスを降順にソート:
c 10
b 20
a 30
dtype: int64
'''
# 値で昇順ソート
print("値を昇順にソート:\n", s.sort_values())
'''
値を昇順にソート:
c 10
b 20
a 30
dtype: int64
'''
# 値で降順ソート
print("値を降順にソート:\n", s.sort_values(ascending=False))
'''
値を降順にソート:
a 30
b 20
c 10
dtype: int64
'''Seriesの結合方法(concat)
concatは、pd.concat([s1, s2]) で結合します。
DataFrameでも使用可能で推奨されています。
s1 = pd.Series([1, 2, 3], index=['a', 'b', 'c'])
s2 = pd.Series([4, 5], index=['d', 'e'])
# concat
s3 = pd.concat([s1, s2])
print("concatでSeriesを結合:\n", s3)
'''
concatでSeriesを結合:
a 1
b 2
c 3
d 4
e 5
dtype: int64
'''Seriesから統計情報の取得
Seriesから統計情報を簡単に取得できます。
.count(), .max(), .min(), .mean(), .std(), .sum()などを活用します。
.describe()を使うと主要な統計情報をまとめて確認できます。
s = pd.Series([10, 20, 30, 40, 50])
print("要素数:", s.count())
# 要素数: 5
print("最大値:", s.max())
# 最大値: 50
print("最小値:", s.min())
# 最小値: 10
print("平均値:", s.mean())
# 平均値: 30.0
print("標準偏差:", s.std())
# 標準偏差: 15.811388300841896
print("合計:", s.sum())
# 合計: 150
# 主要な統計情報をまとめて表示
print("Seriesの統計情報:\n", s.describe())
'''
Seriesの統計情報:
count 5.000000
mean 30.000000
std 15.811388
min 10.000000
25% 20.000000
50% 30.000000
75% 40.000000
max 50.000000
dtype: float64
'''Seriesを使ったデータ分析例
ここでは、サンプルデータとしてCSVファイルを作成します。
DataFrameを利用して、Product, Sales, Discountを作成します。
.to_csv()メソッドを利用することで、csvファイルを作成することができます。
# サンプルデータをCSVファイルに保存
sample_data = pd.DataFrame({
'Product': ['A', 'B', 'C', 'D', 'E'],
'Sales': [150, 200, 300, 250, 400],
'Discount': [5, 10, 15, 10, 20]
})
sample_data.to_csv('sample_data.csv', index=False)
print("サンプルCSVファイルを作成しました: sample_data.csv")
print("sample_data \n", sample_data)
'''
sample_data
Product Sales Discount
0 A 150 5
1 B 200 10
2 C 300 15
3 D 250 10
4 E 400 20
'''データ分析におけるデータ可視化を実施するため、matplotlibを活用します。
必要に応じて、以下のpipコマンドからmatplotlibをインストールしてください。
pip install matplotlib以下は、データを可視化しています。
.read_csv()メソッドにて、csvファイルを読み込みます。
必要に応じて、matplotlib.plotメソッドを活用しデータ可視化を実現しています。
import pandas as pd
import matplotlib.pyplot as plt
# CSVの読み込みとSeriesの作成
df = pd.read_csv('sample_data.csv')
sales = df['Sales']
# データの先頭と末尾の表示
print("データの先頭3件:\n", sales.head(3))
'''
データの先頭3件:
0 150
1 200
2 300
Name: Sales, dtype: int64
'''
print("データの末尾3件:\n", sales.tail(3))
'''
データの末尾3件:
2 300
3 250
4 400
Name: Sales, dtype: int64
'''
# 基本統計量の表示
print("Seriesの統計情報:\n", sales.describe())
'''
Seriesの統計情報:
count 5.00000
mean 260.00000
std 96.17692
min 150.00000
25% 200.00000
50% 250.00000
75% 300.00000
max 400.00000
Name: Sales, dtype: float64
'''
# ヒストグラムの可視化
sales.hist(bins=5)
plt.xlabel('Sales')
plt.ylabel('Frequency')
plt.title('Sales Distribution')
plt.show()
# Seriesの結合による分析
discounts = df['Discount']
combined = pd.concat([sales, discounts], axis=1)
# 散布図による可視化
combined.plot(kind='scatter', x='Discount', y='Sales')
plt.title('Discount vs Sales')
plt.xlabel('Discount (%)')
plt.ylabel('Sales (Units)')
plt.grid(True)
plt.show()pandas|Dataframeの基本的な使い方
pandasにおけるDataFrameの基本的な使い方を解説します。
- データの読み込みや全体像の把握
- データの状態を確認する(行数/列数/重複/選択的表示など)
- データ整形(データ型変更/列名変更/並び替えなど)
- データの欠損状態確認
- 値(欠損)の置き換えや削除
- DataFrameにおける集計
- DataFrameにおける可視化
- DataFrameにおける変数の前処理
- DataFrameによるデータの出力
DataFrameは二次元データであるため、多くのcsv/Excelファイルに適用され利用することができます。
データの読み込みや全体像の把握
ここでは、サンプルデータとして売上データを作成し、各メソッドを解説していきます。
また、欠損値を扱うためにnumpyもインポートしています。
| .head() | 読み込んだデータの先頭5行を表示 |
|---|---|
| .tail() | 読み込んだデータの末尾5行を表示 |
import pandas as pd
import numpy as np
# サンプルデータの作成(売上データの例)
sample_data = pd.DataFrame({
'Date': pd.date_range(start='2023-01-01', periods=10, freq='D'),
'Product': ['A', 'B', 'C', 'A', 'B', 'C', 'A', 'B', 'C', 'A'],
'Sales': [100, 200, np.nan, 150, 250, 300, 200, 220, np.nan, 180],
'Discount': [5, 10, 15, 5, np.nan, 10, 15, 5, 10, np.nan]
})
# CSVファイルに出力(サンプルデータ作成用)
sample_data.to_csv('sales_data.csv', index=False)
# CSVファイルからデータを読み込み
df = pd.read_csv('sales_data.csv')
# 読み込んだデータの先頭5行と末尾5行を表示
print("\n--- 先頭5行 ---")
print(df.head())
'''
--- 先頭5行 ---
Date Product Sales Discount
0 2023-01-01 A 100.0 5.0
1 2023-01-02 B 200.0 10.0
2 2023-01-03 C NaN 15.0
3 2023-01-04 A 150.0 5.0
4 2023-01-05 B 250.0 NaN
'''
print("\n--- 末尾5行 ---")
print(df.tail())
'''
--- 末尾5行 ---
Date Product Sales Discount
5 2023-01-06 C 300.0 10.0
6 2023-01-07 A 200.0 15.0
7 2023-01-08 B 220.0 5.0
8 2023-01-09 C NaN 10.0
9 2023-01-10 A 180.0 NaN
'''巨大なデータになると、全てを表示させることで確認が困難になります。
そのため、.head()や.tail()を利用し、データの一部を確認することで省略化できます。
データの状態を確認する(行数/列数/重複/選択的表示など)
| df.shape | DataFrameの行数と列数のタプルを返す |
|---|---|
| df.index | インデックス情報の確認 |
| df.columns | カラム名の確認 |
| df.dtypes | 各列のデータ型を確認 |
| df.loc[] | ラベル(名前)からデータを抽出 |
| df.iloc[] | 位置(数値)でデータを抽出 |
| df.query() | クエリ文字列を使って条件に合致する行を抽出 |
| df[‘カラム名’].unique() | 指定列のユニークな値(重複しない値)を返す |
| df.drop_duplicates() | 重複する行を削除してユニークなデータのみを残す |
| df.describe() | 数値データに対する基本的な統計量(平均、標準偏差、最大・最小値など)を返す |
# インデックス、カラム、データ型の表示
print("\nインデックス情報:", df.index)
# インデックス情報: RangeIndex(start=0, stop=10, step=1)
print("カラム情報:", df.columns)
# カラム情報: Index(['Date', 'Product', 'Sales', 'Discount'], dtype='object')
print("各列のデータ型:\n", df.dtypes)
'''
各列のデータ型:
Date object
Product object
Sales float64
Discount float64
dtype: object
'''
# loc を使って、ラベルで範囲指定(例:先頭6行の 'Date' と 'Sales' 列)
print("\nlocを使った抽出:")
print(df.loc[:5, ['Date', 'Sales']])
'''
locを使った抽出:
Date Sales
0 2023-01-01 100.0
1 2023-01-02 200.0
2 2023-01-03 NaN
3 2023-01-04 150.0
4 2023-01-05 250.0
5 2023-01-06 300.0
'''
# iloc を使って、位置でデータ抽出(例:最初の3行の2列目以降)
print("\nilocを使った抽出:")
print(df.iloc[0:3, 1:3])
'''
ilocを使った抽出:
Product Sales
0 A 100.0
1 B 200.0
2 C NaN
'''
# query を使った条件指定抽出(Salesが200より大きい行)
print("\nqueryを使った抽出 (Sales > 200):")
print(df.query('Sales > 200'))
'''
queryを使った抽出 (Sales > 200):
Date Product Sales Discount
4 2023-01-05 B 250.0 NaN
5 2023-01-06 C 300.0 10.0
7 2023-01-08 B 220.0 5.0
'''
# 'Product' 列のユニークな値を確認
print("\nユニークな製品名:")
print(df['Product'].unique())
'''
ユニークな製品名:
['A' 'B' 'C']
'''
# 重複データの確認(重複行の数)
print("\n重複行の数:", df.duplicated().sum())
# 重複行の数: 0
# 重複行の削除(重複があれば削除)
df = df.drop_duplicates()
# 統計情報の表示
print("\n基本統計情報:")
print(df.describe())
'''
基本統計情報:
Sales Discount
count 8.000000 8.000000
mean 200.000000 9.375000
std 60.710084 4.172615
min 100.000000 5.000000
25% 172.500000 5.000000
50% 200.000000 10.000000
75% 227.500000 11.250000
max 300.000000 15.000000
'''データ整形(データ型変更/列名変更/並び替えなど)
| df.set_index() | 指定した列を新たなインデックスに設定する。 これにより、データの参照や時系列データの扱いが容易になる。 |
|---|---|
| df.rename() | 列名やインデックス名を変更する。 辞書形式で指定することで、変更前と変更後の対応を示す。 |
| df.sort_values() | 指定した列の値に基づいて並び替える。 ascending引数で昇順・降順の切り替えが可能。 |
| df.to_datetime() | 日付形式の文字列を日時型に変換。 時系列データの扱いに必須。 |
| df.sort_index() | インデックスに基づいて並び替える。 インデックスが日時の場合、日付順にソートできる。 |
| df.resample() | 時系列データの頻度変換や集約を行う(例:日次→月次)。 ※この例ではサンプルデータが短いため実行例は割愛。 |
| df.apply() | 各列または行に対して任意の関数を適用できる。 |
| pd.cut() | 連続値をビン(区間)に分割し、カテゴリ変数に変換。 |
# 'Date' 列をインデックスに設定
df = df.set_index('Date')
print("\n日付をインデックスに設定:")
print(df.head())
'''
日付をインデックスに設定:
Product Sales Discount
Date
2023-01-01 A 100.0 5.0
2023-01-02 B 200.0 10.0
2023-01-03 C NaN 15.0
2023-01-04 A 150.0 5.0
2023-01-05 B 250.0 NaN
'''
# 列名 'Sales' を 'Revenue' に変更
df = df.rename(columns={'Sales': 'Revenue'})
print("\n列名を変更 (Sales → Revenue):")
print(df.head())
'''
列名を変更 (Sales → Revenue):
Product Revenue Discount
Date
2023-01-01 A 100.0 5.0
2023-01-02 B 200.0 10.0
2023-01-03 C NaN 15.0
2023-01-04 A 150.0 5.0
2023-01-05 B 250.0 NaN
'''
# インデックスが文字列の場合は pd.to_datetime() で日時型に変換(ここでは既に日付型ですが、確認の例)
df.index = pd.to_datetime(df.index)
print("\nインデックスを日時型に変換:", df.index.dtype)
# インデックスを日時型に変換: datetime64[ns]
# Revenue 列を基準に降順でソート
df = df.sort_values(by='Revenue', ascending=False)
print("\nRevenueで降順ソート:")
print(df.head())
'''
Revenueで降順ソート:
Product Revenue Discount
Date
2023-01-06 C 300.0 10.0
2023-01-05 B 250.0 NaN
2023-01-08 B 220.0 5.0
2023-01-02 B 200.0 10.0
2023-01-07 A 200.0 15.0
'''
# インデックス(日付)で昇順ソート
df = df.sort_index()
print("\nインデックスで昇順ソート:")
print(df.head())
'''
インデックスで昇順ソート:
Product Revenue Discount
Date
2023-01-01 A 100.0 5.0
2023-01-02 B 200.0 10.0
2023-01-03 C NaN 15.0
2023-01-04 A 150.0 5.0
2023-01-05 B 250.0 NaN
'''データの欠損状態確認
| df.isnull() | 各セルが欠損値かどうかをTrue/Falseで示すDataFrameを返す。 |
|---|---|
| df.any() | 各列(または行)に欠損値が存在するかをブール値で返す(Trueなら欠損が存在)。 |
# 各セルの欠損状況を確認
print("\n各セルの欠損状況:")
print(df.isnull().head())
'''
各セルの欠損状況:
Date Product Sales Discount
0 False False False False
1 False False False False
2 False False True False
3 False False False False
4 False False False True
'''
# 列ごとに欠損値が存在するか確認
print("\n各列に欠損があるか:")
print(df.isnull().any())
'''
各列に欠損があるか:
Date False
Product False
Sales True
Discount True
dtype: bool
'''値(欠損)の置き換えや削除
| df.fillna() | 欠損値を指定した値で埋める。 例えば平均値や0などで補完する場合に利用する。 |
|---|---|
| df.dropna() | 欠損値を含む行または列を削除。 |
| df.replace() | 特定の値を別の値に置き換える。 |
| df.mask() | 条件に合致する値を指定の値に置き換える(条件を反転させた where() との違いに注意)。 |
| df.drop() | 指定したラベル(行または列)を削除。ここでは、主に重複の削除以外の用途で使います。 |
# 列名 'Sales' を 'Revenue' に変更
df = df.rename(columns={'Sales': 'Revenue'})
print("\n列名を変更 (Sales → Revenue):")
print(df.head())
'''
列名を変更 (Sales → Revenue):
Date Product Revenue Discount
0 2023-01-01 A 100.0 5.0
1 2023-01-02 B 200.0 10.0
2 2023-01-03 C NaN 15.0
3 2023-01-04 A 150.0 5.0
4 2023-01-05 B 250.0 NaN
'''
# 'Discount' 列の欠損値を 0 で埋める
df['Discount'] = df['Discount'].fillna(0)
# Revenue 列に欠損があれば、その行を削除(この例ではすでに欠損行は drop_duplicates() で除外済みですが、例として)
df = df.dropna(subset=['Revenue'])
# 'Product' 列の値 'A' を 'Alpha' に置き換える
df['Product'] = df['Product'].replace('A', 'Alpha')
print("\n欠損値処理・置換後のデータ:")
print(df.head())
'''
欠損値処理・置換後のデータ:
Date Product Revenue Discount
0 2023-01-01 Alpha 100.0 5.0
1 2023-01-02 B 200.0 10.0
3 2023-01-04 Alpha 150.0 5.0
4 2023-01-05 B 250.0 0.0
5 2023-01-06 C 300.0 10.0
'''DataFrameにおける集計
| df.value_counts() | 各値の出現回数をカウント(主にSeriesに対して利用)。 |
|---|---|
| df.groupby() | 指定したキーでデータをグループ化し、各グループごとに集計処理。 |
| df.diff() | 隣接する行の差分を計算。 時系列データの変化量を求める際に便利。 |
| df.rolling() | ローリング(移動)ウィンドウを定義し、そのウィンドウごとに集計処理(例:移動平均)。 |
| df.pct_change() | 前の値と比較してパーセンテージ変化を計算。 |
# 列名 'Sales' を 'Revenue' に変更
df = df.rename(columns={'Sales': 'Revenue'})
print("\n列名を変更 (Sales → Revenue):")
print(df.head())
'''
列名を変更 (Sales → Revenue):
Date Product Revenue Discount
0 2023-01-01 A 100.0 5.0
1 2023-01-02 B 200.0 10.0
2 2023-01-03 C NaN 15.0
3 2023-01-04 A 150.0 5.0
4 2023-01-05 B 250.0 NaN
'''
# 'Product' 列の値ごとの出現回数(value_countsは Series に対して使用)
print("\n製品ごとの出現回数:")
print(df['Product'].value_counts())
'''
製品ごとの出現回数:
Product
A 4
B 3
C 3
Name: count, dtype: int64
'''
# groupby を使って、各製品ごとのRevenueの合計を算出
grouped = df.groupby('Product')['Revenue'].sum()
print("\n製品ごとのRevenue合計:")
print(grouped)
'''
製品ごとのRevenue合計:
Product
A 630.0
B 670.0
C 300.0
Name: Revenue, dtype: float64
'''
# diff を使って、隣接行間のRevenueの差分を計算
df['Revenue_diff'] = df['Revenue'].diff()
print("\nRevenueの差分:")
print(df[['Revenue', 'Revenue_diff']].head())
'''
Revenueの差分:
Revenue Revenue_diff
0 100.0 NaN
1 200.0 100.0
2 NaN NaN
3 150.0 NaN
4 250.0 100.0
'''
# rolling を使って、3期間の移動平均(Rolling Mean)を計算
df['Revenue_MA'] = df['Revenue'].rolling(window=3).mean()
print("\n3期間移動平均 (Revenue_MA):")
print(df[['Revenue', 'Revenue_MA']].head())
'''
3期間移動平均 (Revenue_MA):
Revenue Revenue_MA
0 100.0 NaN
1 200.0 NaN
2 NaN NaN
3 150.0 NaN
4 250.0 NaN
'''
# pct_change を使って、Revenueの前期間比(変化率)を計算
df['Revenue_pct_change'] = df['Revenue'].pct_change()
print("\nRevenueの前期間比:")
print(df[['Revenue', 'Revenue_pct_change']].head())
'''
Revenueの前期間比:
Revenue Revenue_pct_change
0 100.0 NaN
1 200.0 1.000000
2 NaN 0.000000
3 150.0 -0.250000
4 250.0 0.666667
'''DataFrameにおける可視化
| df.plot() | DataFrameやSeriesのデータを手軽に可視化できる。 引数でグラフの種類(折れ線、散布図、棒グラフなど)を指定可能。 |
|---|---|
| df.corr() | 各数値列間の相関係数を計算し、相関行列を返す。 データ間の関係性を把握するために使う。 |
| df.pivot() | データのピボット(行・列の入れ替え)を行い、集計しやすい形に変換。 |
# Revenueの推移を折れ線グラフで可視化
df['Revenue'].plot(title='Revenue Over Time', figsize=(8, 4))
plt.xlabel('Date')
plt.ylabel('Revenue')
plt.show()
# 数値データ間の相関行列を計算し表示
print("\n相関行列:")
print(df.corr())
# pivot の例:ここでは、ProductごとにDiscountの平均値をピボットテーブルで表示
pivot_table = df.pivot_table(values='Discount', index=df.index, columns='Product', aggfunc='mean')
print("\nPivot Table (Discountの平均値):")
print(pivot_table)DataFrameにおける変数の前処理
| df.get_dummies() | カテゴリ変数を0/1のダミー変数に変換。 機械学習アルゴリズムで数値データしか扱えない場合に有用。 |
|---|
# 'Product' 列をダミー変数化(One-Hot Encoding)
df_dummies = pd.get_dummies(df, columns=['Product'])
print("\nOne-Hot Encoding後のデータ:")
print(df_dummies.head())
'''
One-Hot Encoding後のデータ:
Date Revenue Discount Product_A Product_B Product_C
0 2023-01-01 100.0 5.0 True False False
1 2023-01-02 200.0 10.0 False True False
2 2023-01-03 NaN 15.0 False False True
3 2023-01-04 150.0 5.0 True False False
4 2023-01-05 250.0 NaN False True False
'''DataFrameによるデータの出力
| df.to_csv() | DataFrameをCSVファイルとして出力。 これにより、前処理や分析後のデータを保存・共有できる。 |
|---|
# 処理済みのデータをCSVファイルに保存
df.to_csv('processed_sales_data.csv')
print("\n処理済みデータを 'processed_sales_data.csv' に出力しました。")