Googleマップを利用して企業・店舗情報を取得したい場面が案件によって発生します。
本記事では、ランサーズ案件にてGoogleマップ検索結果の情報収集を依頼されたため備忘録として記載します。
- Googleマップのスクレイピング方法
- Seleniumライブラリの使い方
- スクレイピングプログラムの解説
▼【無料教材】Pythonを学びたい人へ資料を配布中▼
本記事をお読み頂いているプログラミング初学者向けに、本サイトはPythonを始めるためのガイドを配布しています。
以下に無料配布するPython資料をご紹介します。
- Python入門ガイド
- Python製デスクトップ用GUIライブラリガイド
- Python用学習ロードマップシート
- Tkinter製テンプレート集
- DXアイデア100選スライド
限られた時間を情報収集に極力かけず、他言語よりも「なぜ今Pythonを選ぶべきか」をガイドにしています。
プログラミングにおいて、情報収集の時間短縮は学習時間の短縮に直結します。
開発環境→基礎学習→ライブラリ/FW→アプリ開発に至る学習シートを配布しています。
また、定期アンケートによって「リアルな声」を反映して常に教材改善のアップデート情報を受け取れます。
\ メルアドのみで今すぐ受け取れます /
GoogleMaps(Googleマップ)とは
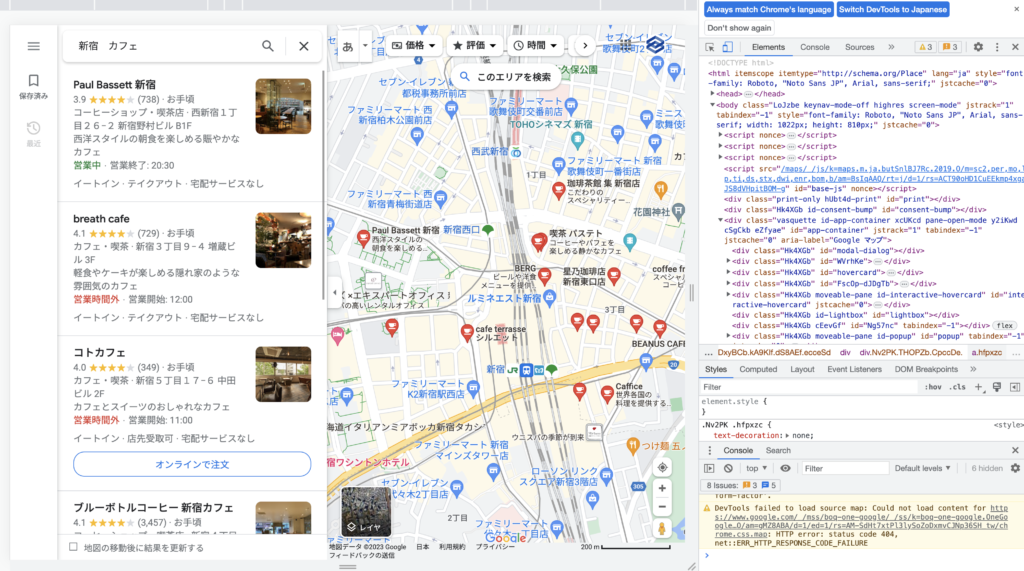
GoogleMaps(Googleマップ)は、Googleが提供する検索条件から場所を特定するサービスです。
多くの方々が利用する中で、会社・店舗などの情報が登録されており、名称・住所・電話番号・URLなど詳細情報を確認できます。
現在も企業・個人事業主ともに情報収集先として活用されている状態です。
GoogleMaps(Googleマップ)のスクレイピング方法
GoogleMaps(Googleマップ)にて効率的データを収集するのに役立つのが「Webスクレイピング」です。
一般的に、以下の3つのスクレイピング方法が挙げられます。
- Places API of Google Maps Platform (Google Maps API)
- 既存のスクレイピング関連サービス/ツール
- Pythonなどのスクレイピングプログラム作成
それぞれの方法にメリットとデメリットが存在しており、予算がある中でリストデータをどのように確保するのかを考慮して選ぶ必要があります。
| 方法 | 金額 | 初期構築 |
|---|---|---|
| Google Places API | 従量課金制 | プログラムが必要 |
| 既存サービス | 定額制 | 不要 |
| Pythonプログラム | 無料 | プログラムが必要 |
Pythonプログラムに関しては、自身でスクレイピングプログラムを構築するかPlaces APIをコールしてGoogleが持つ膨大なデータを引っ張ってくるのかといった違いになります。
本記事は後半でPythonプログラムによるスクレイピングとAPIを利用した方法を記載していますが、すぐにでもリストデータを収集したい場合、既存サービス/ツールを検討するとよいでしょう。
GoogleMaps(Googleマップ)のスクレイピングについて
GooleMaps(Googleマップ)は、静的ページと違って動的ページに位置付けられます。
そのため、動的ページ用に処理できるスクレイピングプログラムが求められます。
静的ページと動的ページの違い

静的ページは、Webサーバーで用意されたHTMLファイルを読み込み、ブラウザ側で表示されます。
一方で、動的ページはリクエストの度にHTMLファイルを再生成します。
そのため、Webスクレイピングの観点から動的ページより静的ページが処理しやすいです。
なぜなら、リクエストに応じて変化する動的ページはスクレイピング処理だけでなく、ブラウザ操作もプログラムする必要があるためです。
静的・動的ページに対するライブラリの使い分け
| ライブラリ名 | 静的/動的 | メリット/デメリット |
|---|---|---|
| requests | 静的ページに有効 | ・URLにて特定できるため静的ページに活用しやすい ・件数が多くても収集速度が良い ・ブラウザ操作はできない |
| BeautifulSoup | 静的/動的ページに有効 | ・HTML/XMLデータの解析に利用 ・Webサイト内の情報を特定/抽出 |
| Selenium | 動的ページに有効 | ・動的ページを操作する必要があるため ・ブラウザ操作が可能 ・操作数と件数が多いほど処理コードが増える |
Googleマップの場合は動的ページであるため、Seleniumライブラリを利用する必要があります。
利用する理由としては、ブラウザの検索表示結果からスクロール操作を実施しなければならないためです。
スクロール操作を実施することで、検索結果全てを一度HTML上で展開する結果を得られます。
Seleniumの操作方法
本記事では、動的ページであるGoogleMapsを利用するため、Seleniumを利用します。
また、Seleniumによるwebスクレイピング時に多用する操作コードを記載します。
| メソッド名 | 説明 |
|---|---|
| find | id, class, xpathなど指定した属性データを抽出 |
| send_keys | 入力データをブラウザに送信 |
| click | Enterキー |
Seleniumにおける各メソッドの使い方を詳細に知りたい人は、「【業務自動化】Seleniumとは?インストールから使い方まで徹底解説!」を一読ください。

SeleniumのWebDriverWaitの使い方
Seleniumを利用してブラウザ操作する場合、ブラウザに対する待機時間もうまく処理する必要があります。
また、Seleniumにおけるエラーの原因は、指定した要素が見つからないことがほとんどです。
人間の操作より遥かに速い操作でプログラムが処理するため、指定要素の存在有無でエラーを引き起こします。
ここでは以下に3つの待機処理を紹介します。
- .implicitly_wait()による暗黙的な待機処理
- WebDriverWait.until()による明示的な待機処理
- time.sleep()の待機処理
また、Seleniumで待機処理を実施する場合に以下のWebDriverWaitモジュールをインポートしておきます。
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as ECSeleniumによるWebDriverWaitの使い方(各待機処理の方法)を知りたい人は、「【ブラウザを完全制御】SeleniumにおけるWebDriverの使い方を徹底解説!」を一読ください。

webdriver-managerのインストール・使い方(自動更新)
Chrome等のブラウザは定期的にアップデートされ、古いバージョンのwebdriverが使用できなくなるケースがあります。
残念ながら、webdriverのバージョン管理及びアップデートは、手動で実施する必要があり手間になります。
そのため、webdriverを自動更新するライブラリであるwebdriver-managerのインストールをおすすめします。
pip install webdriver-manager上記コマンド実施後、Successfullyが表示されればインストール完了です。
また、Selenium3とSelenium4によってPythonファイルへの記述方法が異なります。
# Selenium 3
from selenium import webdriver
from webdriver_manager.chrome import ChromeDriverManager
driver = webdriver.Chrome(ChromeDriverManager().install())# Selenium 4
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from webdriver_manager.chrome import ChromeDriverManager
driver = webdriver.Chrome(service=Service(ChromeDriverManager().install()))
上記コードを記述することで、ブラウザバージョンのアップデートの度に、webdriver更新時の手間が省けます。
SeleniumによるGoogleMapsスクレイピングプログラム
ここから、SeleniumによるGoogleマップのスクレイピングプログラムについて解説します。
以下の流れでPythonプログラムを作成しています。
- 必要な各種ライブラリ
- Webdriverのセットアップ
- ブラウザ操作によるGoogleマップ検索結果
- 動的ページをスクロール
- 全データ表示後に各データをスクレイピング
- Seleniumによるスクレイピングプログラム実行結果
必要なライブラリ
以下で、本プログラムで使用するライブラリ・モジュールを記載します。
| ライブラリ名 | 説明 |
|---|---|
| selenium | ブラウザ操作とHTML要素から属性データ抽出 |
| time | 動的ページの読み込みに合わせて待機時間を設ける |
| csv | CSVファイル出力 |
| traceback | エラー発生時の確認用 |
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.common.by import By
from selenium.webdriver.chrome.options import Options
import time
import csv
import tracebackWebdriverのセットアップ
def setup_driver():
options = Options()
options.headless = False
return webdriver.Chrome(r"/Path/to/chromedriver", options=options)- WebDriverの設定を行い、Chromeドライバーを作成します。
- オプションを設定し、ヘッドレスモードをオフにして可視化しています。(True:ヘッドレスモードオン)
- Chromeドライバーのインスタンスを返します。
ブラウザ操作によるGoogleマップ検索結果
def search_google_map(driver, search_word):
url = "https://www.google.co.jp/maps/"
driver.get(url)
time.sleep(3)
search_box = driver.find_element(By.ID, "searchboxinput")
search_box.send_keys(search_word)
time.sleep(1)
search_button = driver.find_element(By.XPATH, "//*[@id='searchbox-searchbutton']")
search_button.click()
time.sleep(3)- Google マップの検索ページにアクセスします。
- 検索ワードを指定し、検索ボックスに入力します。
- 検索ボタンをクリックして検索を実行します。
- 一定の待機時間を挟みます。
動的ページをスクロール
def scroll_to_bottom(driver):
while True:
before_count = len(driver.find_elements(By.CLASS_NAME, "m6QErb.DxyBCb.kA9KIf.dS8AEf.ecceSd .Nv2PK.THOPZb.CpccDe"))
scroll_elem = driver.find_element_by_xpath("/html/body/div[3]/div[9]/div[9]/div/div/div[1]/div[2]/div/div[1]/div/div/div[2]/div[1]")
for _ in range(3):
scroll_elem.send_keys(Keys.END)
time.sleep(1)
after_count = len(driver.find_elements(By.CLASS_NAME, "m6QErb.DxyBCb.kA9KIf.dS8AEf.ecceSd .Nv2PK.THOPZb.CpccDe"))
if before_count == after_count:
break
time.sleep(3)- ページの一番下までスクロールします。
- スクロール前後の要素数を比較し、変化がなくなるまでスクロールを繰り返します。
- 一定の待機時間を挟みます。
Googleマップは、定期的にクラス・ID等の変更やHTML構造の変更を実施するため、エラー発見のためにtracebackを設けています。
エラーが発生した場合は、クラス名やxpathなどを見直してみましょう。
全データ表示後に各データをスクレイピング
def scrape_company_data(driver, search_word):
result_list = []
elems_1 = driver.find_element(By.CLASS_NAME, "m6QErb.DxyBCb.kA9KIf.dS8AEf.ecceSd")
elems_2 = elems_1.find_elements(By.CLASS_NAME, "Nv2PK.THOPZb.CpccDe")
for href in elems_2:
result_list.append(href.find_element(By.TAG_NAME, "a").get_attribute('href'))
for result in result_list:
try:
driver.get(result)
time.sleep(3)
company_name = driver.find_element(By.CLASS_NAME, "DUwDvf.fontHeadlineLarge").get_attribute('innerText')
address = driver.find_element(By.CLASS_NAME, "RcCsl.fVHpi.w4vB1d.NOE9ve.M0S7ae.AG25L").get_attribute('innerText')
with open(search_word + '.csv', 'a', newline='', encoding='utf8') as outcsv:
csvwriter = csv.writer(outcsv)
csvwriter.writerow([company_name, address])
except:
traceback.print_exc()
print("next")- スクロールした結果から取得した要素の詳細データをスクレイピングします。
- 各要素の詳細ページにアクセスし、会社名/店舗名と住所を取得します。
- CSVファイルに取得したデータを追記します。
- 例外が発生した場合は、トレースバックを表示し、次の要素のスクレイピングに進みます。
Seleniumによるスクレイピングプログラム実行結果
最終的な全体コードは以下に記載します。
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.common.by import By
from selenium.webdriver.chrome.options import Options
import time
import csv
import traceback
def setup_driver():
options = Options()
options.headless = False
return webdriver.Chrome(r"/path/to/chromedriver", options=options)
def search_google_map(driver, search_word):
url = "https://www.google.co.jp/maps/"
driver.get(url)
time.sleep(3)
search_box = driver.find_element(By.ID, "searchboxinput")
search_box.send_keys(search_word)
time.sleep(1)
search_button = driver.find_element(By.XPATH, "//*[@id='searchbox-searchbutton']")
search_button.click()
time.sleep(3)
def scroll_to_bottom(driver):
while True:
before_count = len(driver.find_elements(By.CLASS_NAME, "m6QErb.DxyBCb.kA9KIf.dS8AEf.ecceSd .Nv2PK.THOPZb.CpccDe"))
scroll_elem = driver.find_element_by_xpath("/html/body/div[3]/div[9]/div[9]/div/div/div[1]/div[2]/div/div[1]/div/div/div[2]/div[1]")
for _ in range(3):
scroll_elem.send_keys(Keys.END)
time.sleep(1)
after_count = len(driver.find_elements(By.CLASS_NAME, "m6QErb.DxyBCb.kA9KIf.dS8AEf.ecceSd .Nv2PK.THOPZb.CpccDe"))
if before_count == after_count:
break
time.sleep(3)
def scrape_company_data(driver, search_word):
result_list = []
elems_1 = driver.find_element(By.CLASS_NAME, "m6QErb.DxyBCb.kA9KIf.dS8AEf.ecceSd")
elems_2 = elems_1.find_elements(By.CLASS_NAME, "Nv2PK.THOPZb.CpccDe")
for href in elems_2:
result_list.append(href.find_element(By.TAG_NAME, "a").get_attribute('href'))
for result in result_list:
try:
driver.get(result)
time.sleep(3)
company_name = driver.find_element(By.CLASS_NAME, "DUwDvf.fontHeadlineLarge").get_attribute('innerText')
address = driver.find_element(By.CLASS_NAME, "RcCsl.fVHpi.w4vB1d.NOE9ve.M0S7ae.AG25L").get_attribute('innerText')
with open(search_word + '.csv', 'a', newline='', encoding='utf8') as outcsv:
csvwriter = csv.writer(outcsv)
csvwriter.writerow([company_name, address])
except:
traceback.print_exc()
print("next")
def main():
search_word = "新宿 カフェ"
driver = setup_driver()
search_google_map(driver, search_word)
scroll_to_bottom(driver)
scrape_company_data(driver, search_word)
driver.quit()
if __name__ == "__main__":
main()取得できたデータとCSVファイル
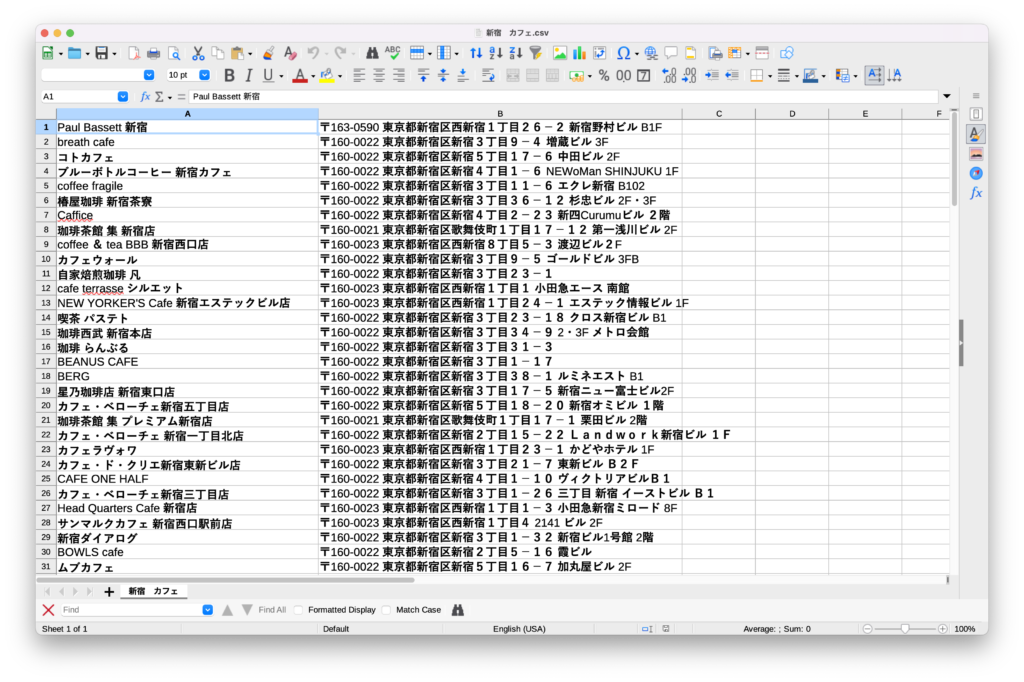
無事ヒットした件数分をスクレイピングできました。
詳細データをさらに取得したい場合は、電話番号・URLなどを抽出するコードを追記すればOKです。
Googleマップからクチコミをスクレイピングする方法
Googleマップからクチコミをスクレピングする方法として、GCP(Google Cloud Platform)を利用したコードを紹介します。
また、以下の流れに沿って実行環境を整備してください。
- GCPプロジェクト作成とAPI有効化
- googlemapsライブラリのインストール
- pandasライブラリのインストール
上記の手順に沿って実行環境が整ったら、以下のプログラムコードを実行します。
import googlemaps
import pandas as pd
# Google Places APIキーを設定
API_KEY = 'YOUR_GOOGLE_PLACES_API_KEY'
gmaps = googlemaps.Client(key=API_KEY)
# 店舗のURLからPlace IDを取得する関数
def get_place_id_from_url(place_url):
place_id = place_url.split('placeid=')[-1]
return place_id
# Place IDから口コミデータを取得する関数
def get_reviews(place_id):
place_details = gmaps.place(place_id=place_id, fields=['reviews'])
reviews = place_details.get('result', {}).get('reviews', [])
return reviews
# 口コミデータをCSVファイルに保存する関数
def save_reviews_to_csv(reviews, filename='reviews.csv'):
review_list = []
for review in reviews:
review_list.append({
'author_name': review['author_name'],
'rating': review['rating'],
'text': review['text'],
'time': review['relative_time_description']
})
df = pd.DataFrame(review_list)
df.to_csv(filename, index=False, encoding='utf-8-sig')
# 店舗のURLを指定
place_url = 'https://www.google.com/maps/place/?q=placeid:YOUR_PLACE_ID'
# Place IDを取得
place_id = get_place_id_from_url(place_url)
# 口コミデータを取得
reviews = get_reviews(place_id)
# 口コミデータをCSVファイルに保存
save_reviews_to_csv(reviews)上記のサンプルコードは、以下のポイントに沿って作成しています。
- Google Places APIを使用し特定店舗のPlace ID取得
- Place IDを使用し店舗の詳細情報(口コミデータ)取得
- 取得した口コミデータをCSVファイルに保存
Googleマップから各店舗のURLを大量に取得し、for文といったループを利用することで複数店舗に対応したクチコミ用スクレイピングプログラムに改善できます。
GoogleMapデータ収集に役立つスクレイピングツール
上述してきたPythonライブラリであるSeleniumによるスクレイピングツール作成以外にも、データ収集方法はいくつかあります。
- ノーコードスクレイピングツール
- その他Pythonライブラリ
- GitHubなどのオープンソースプロジェクト
- Web Scraperなどのブラウザ拡張機能
- AIエージェントによるAIスクレイピング
特に、金銭面に余裕がある場合や時間短縮を考える場合、有料サービスであるスクレイピングツールあるいはAIエージェントを活用するとよいです。
上記のスクレイピング方法の詳細に関しても解説します。
ノーコードスクレイピングツール
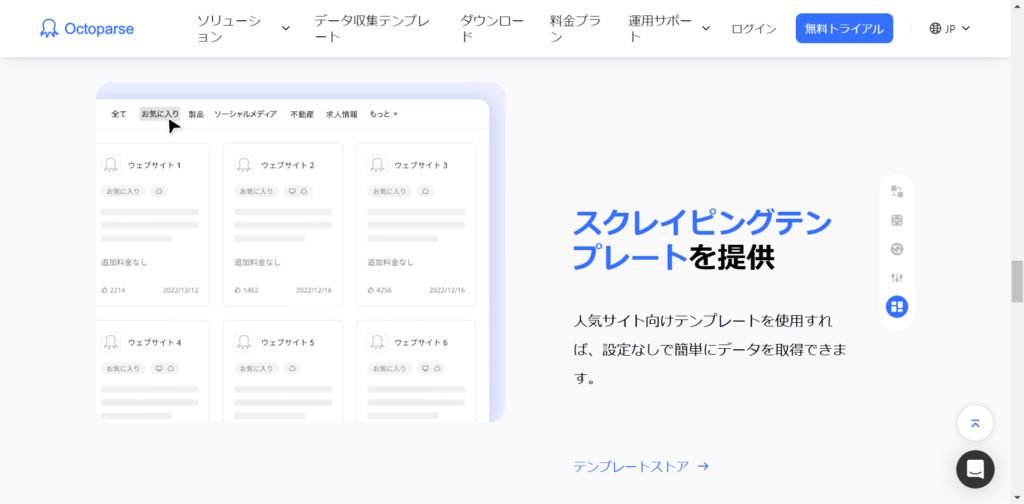
有名なWebスクレイピングサービスはOctoparseが挙げられます。
実際にスクレイピングテンプレートが提供されており、Google Mapを始め100件近く有名サイトや有名アプリの手が届きづらいリストデータまで収集できるようになります。

その他Pythonライブラリ
上述してきたSelenium以外にも、スクレイピングに利用できるライブラリやフレームワークがあります。
- requests, BeautifulSoup
- Scrapy
ライブラリであればrequestsやBeautifulSoupを利用することも検討するとよいでしょう。
また、Python環境の一つであるAnacondaをインストールすることで、スクレイピング用PythonフレームワークであるScrapyも検討の余地があります。
上記はコーディング作業が必要になりますが、使用方法が分かれば狙ったサイトやサービスからスクレイピングデータを自由に取得できるようになります。
GitHubなどのオープンソースプロジェクト
GitHubといったオープンソース共有機能サービスを利用することで、他者が生み出したスクレイピングプロジェクトが数多く存在します。
特にGitHubの大きなメリットは、他者がある程度質を担保したプログラムとして公開されている点です。
また、多くの労力と思考時間をかけて作成されているため、読み解くことができればプログラム開発の時間節約が見込めます。
Web Scraperなどのブラウザ拡張機能
次に考えられるケースは、Googleのブラウザ拡張機能によるスクレイピング方法です。
- Web Scraper
- Easy Scraper
- Nocoding Scraper
ブラウザ拡張機能は検索すれば様々なものが見つかります。
選んだ拡張機能によっては、クローリング機能や高品質な検出機能を持ったデータ収集が可能になり、ノーコードであってもあなたのスクレイピング目的を実現できます。
AIエージェントによるAIスクレイピング
2024年から膨大な数のAIエージェントサービスが出現しました。
OpenAIによるChatGPTを始め、GoogleやMicrosoftなどビッグIT企業からマイナーAIまで様々です。
AIによる作業効率化はスクレイピング作業にも多大に影響されており、AIエージェントを利用したスクレイピング方法を探せば、最適なスクレイピング情報を見つけることも簡単です。
金銭面に余裕があれば、まずAIによるスクレイピング方法から検索することをお勧めします。