ランサーズ等のクラウドソーシングサイトでよく見かけるスクレイピング案件があります。
スクレイピング案件と言っても、膨大なサイト数であるため、適宜対象サイトに沿ったスクレイピングプログラムを作成する必要があります。
本記事では、以下の内容を徹底解説します。
- クローリングとスクレイピングの違い
- スクレイピング対象になるサイト例
- クローリングプログラム
- スクレイピングプログラム
▼【無料教材】Pythonを学びたい人へ資料を配布中▼
本記事をお読み頂いているプログラミング初学者向けに、本サイトはPythonを始めるためのガイドを配布しています。
以下に無料配布するPython資料をご紹介します。
- Python入門ガイド
- Python製デスクトップ用GUIライブラリガイド
- Python用学習ロードマップシート
- Tkinter製テンプレート集
- DXアイデア100選スライド
限られた時間を情報収集に極力かけず、他言語よりも「なぜ今Pythonを選ぶべきか」をガイドにしています。
プログラミングにおいて、情報収集の時間短縮は学習時間の短縮に直結します。
開発環境→基礎学習→ライブラリ/FW→アプリ開発に至る学習シートを配布しています。
また、定期アンケートによって「リアルな声」を反映して常に教材改善のアップデート情報を受け取れます。
\ メルアドのみで今すぐ受け取れます /
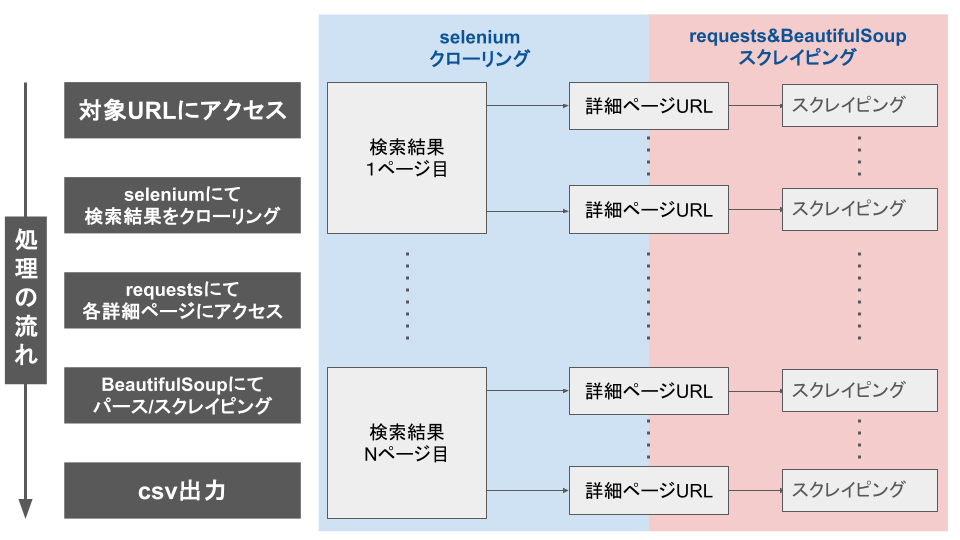
クローリングとスクレイピングの違い

クローリングとは、対象サイトの各ページを巡回することを指します。
いわゆるページ遷移型のスクレイピングプログラムは、クローリングプログラムが作成できるかが重要になります。
また、クローリングプログラムを作成するためには、静的・動的ページサイトのHTML構造を理解する必要があります。

スクレイピングとは、対象ページ内のデータを取得・抽出することを指します。
クローリングプログラムによって各ページの表示結果から企業や店舗の詳細ページURLを取得することで、各URLにアクセスしスクレイピングを実施する必要があります。
そのため、ページ遷移型のスクレイピングプログラムを作成したい場合、クローリングとセットになることを意識しましょう。
ページ遷移型のスクレイピング対象になるサイトとは
ページ遷移は、対象サイトが静的ページと動的ページのどちらにおいても実施する可能性があります。
そのため、静的ページと動的ページの特徴を捉えておくと、プログラムに反映させやすいです。
| ページの種類 | ページごとの特徴 |
|---|---|
| 静的ページ | ・一度読み込めばHTML内の情報が取得できる ・URLの認識がしやすい(扱いやすい) |
| 動的ページ | ・特定のアクションしないと読み込めないデータがある ・URLの認識がしにくい(扱いにくい) |
具体的なデータパターンとサイト例は以下になります。
| データパターン | サイト例 |
|---|---|
| 企業データ | マイナビ・リクナビ等の就職/転職サイト |
| 施設・店舗データ | Googleマップ、ホットペッパービューティ、食べログなど |
| 個人のアカウントデータ | SNSサイト |
やはり大手のポータルサイト・総合サイトは、詳細情報が記載されているページを各種設けており、HTML構造としてもテーブルデータで持たせているケースが多いです。
そのため、有名な情報サイトのスクレイピングプログラムを作成しておけば、大概のリストを収集することが可能になります。
静的ページと動的ページの違い

静的ページは、Webサーバーで用意されたHTMLファイルを読み込み、ブラウザ側で表示されます。
一方で、動的ページはリクエストの度にHTMLファイルを再生成します。
そのため、Webスクレイピングの観点から動的ページより静的ページが処理しやすいです。
なぜなら、リクエストに応じて変化する動的ページは、スクレイピング処理だけでなく、ブラウザ操作もプログラムする必要があるためです。
より詳しく動的ページのスクレイピングコード等を確認したい人は、「【業務自動化】Seleniumとは?インストールから使い方まで徹底解説!」を一読ください。

静的ページ遷移型のおすすめライブラリ
| ライブラリ名 | 静的/動的 | メリット/デメリット |
|---|---|---|
| requests | 静的ページに有効 | ・URLがあれば静的ページに活用しやすい ・件数が多くても収集速度が良い ・ブラウザ操作はできない |
| BeautifulSoup | 静的ページに有効 | ・HTML解析(パース)に利用される ・HTML要素から属性値を利用してデータを特定できる |
requestsはブラウザ操作ができない分、Seleniumに比べると収集速度は速いです。
例えば、URLの中ですでにページ番号が記載されていると、ページ用変数を用意しfor文で回すだけで一気にデータ収集が可能になります。
動的ページ遷移型のおすすめライブラリ
| ライブラリ名 | 静的/動的 | メリット/デメリット |
|---|---|---|
| Selenium | 動的ページに有効 | ・静的/動的に限らず様々なページに活用できる ・ブラウザ操作が含まれるため、時間を要する |
最近では、静的ページであってもURL内にページ番号を表示せず秘匿にするサイトも増えています。
スクレイピング対策の一つではありますが、URLのみでページ遷移が不可能な場合はSeleniumによるクローリングにて詳細ページURLを大量に取得します。
各詳細ページのリストデータが作成できたらrequests&BeautifulsoupにてHTML解析後スクレイピングで目的のデータを収集といった流れがよいです。
ログイン型のスクレイピング対象になるサイトとは
対象サイトによっては、セッションなしのログイン処理によりセッション切れが発生するケースがあります。
理由は、対象サイト側でこちらが予期していないセキュリティ対策を講じている可能性があります。
- ユーザーエージェントの問題
- ログイン画面の表示時点でCookie発行して整合性が取れない
- トークン情報の付与が求められる
上記のようなケースでログイン処理が実行できない、あるいはセッション切れが発生する場合にセッションインスタンスを作成し、ログイン画面をGETしてCookieやトークン情報を得ておく必要があるでしょう。
.session()メソッドを利用したログイン処理の記述方法を知りたい人は、「【データ収集に役立つ】requestsとは?インストールから使い方まで徹底解説!」を一読ください。

requestsのメソッドの使い方
ここでは、特にクローリング後に取得した各URLに対して利用するrequestsについて解説します。
requestsでは、以下の4つが代表的なメソッドになります。
| メソッド名 | 説明 |
|---|---|
| requests.get() | サーバーから情報を取得 |
| requests.post() | サーバーへ情報を送信 |
| requests.put() | サーバーの情報を更新 |
| requests.delete() | サーバーの情報を削除 |
本記事では、企業ごとのURLに対してWebスクレイピングを利用するため、.get()メソッドを重点的に解説します。
requests.get()の引数の使い方
Webスクレイピングといったデータ収集などで頻繁に利用されるのがrequests.get()になります。
res = requests.get(URL, 任意の引数).get()メソッドを利用することで直感的に操作することができます。
また、以下が主な引数になります。
| メソッド名 | 必須/任意 | 説明 |
|---|---|---|
| URL | 必須 | 対象URL |
| headers | 任意 | リクエスト時にヘッダーデータを辞書で指定 |
| params | 任意 | リクエスト時にURLのクエリパラメータを辞書で指定 |
| cookies | 任意 | リクエスト時にクッキーを辞書で指定 |
| timeout | 任意 | リクエスト時のタイムアウトを指定 |
スクレイピング業務では、引数にURLのみを利用することが多いです。
requests.get()によるresponseオブジェクトの確認
リクエスト後の戻り値(応答)として、responseオブジェクトが返ってきます。
以下がresponseオブジェクトの属性値になります。
| 属性 | 説明 |
|---|---|
| status_code | ステータスコード |
| headers | レスポンスヘッダーのデータ |
| content | レスポンスのバイナリデータ |
| text | レスポンスのテキストデータ |
| encoding | エンコーディング(変換方式:utf-8など) |
| cookies | クッキーデータ |
ここでは、responseオブジェクトのtext属性データのみを利用したスクレイピングプログラムになります。
requestsライブラリをさらに理解したい人は、「【データ収集に役立つ】requestsとは?インストールから使い方まで徹底解説!」を一読ください。

BeautifulSoupの代表的なメソッドの使い方
HTMLデータを解析した後、指定した箇所のデータを抽出する必要があります。
本記事では、スクレイピングの際に利用するBeautifulSoupの代表的なメソッドを記載します。
| タイプ | 1要素だけ返す | 全要素をリストで返す | 引数(検索条件指定) |
|---|---|---|---|
| find系 | find() | find_all() | 要素名, 属性指定(キーワード引数) |
| select系 | select_one() | select() | CSSセレクタ |
機能はどちらも同じですが、引数の違いによって探し出すアプローチ方法が異なります。
ただし、HTMLデータによってはクラス/idに対して属性値を持たないデータがあるため、その場合はselect系を利用しましょう。
BeautifulSoupをさらに理解したい人は、「【チートシート】BeautifulSoup4とは?インストールから使い方まで徹底解説!」を一読ください。

Seleniumのメソッドの使い方
代表的なSeleniumのメソッドは以下の4つです。
| メソッド名 | 説明 |
|---|---|
| .get() | 対象URLを指定しアクセス/データ取得するメソッド |
| .find_element_by_〇〇(“”) | Selenium3にて利用されるfind系メソッド |
| .find_element(By.〇〇, “xx”) | Selenium4にて利用されるfind系メソッド |
| .send_keys() | 対象にデータ送信するメソッド |
| .click() | 対象をEnterするメソッド |
本記事では、ブラウザ操作に利用するため、上記メソッドを重点的に解説します。
Seleniumにおける各メソッドの使い方を詳細に知りたい人は、「【業務自動化】Seleniumとは?インストールから使い方まで徹底解説!」を一読ください。

特定サイトをページ遷移するクローリング方法
ここでは、マイナビを例に実践します。
- 必要な各種ライブラリをインポート
- 出力フォルダとCSVファイルを作成
- Seleniumの設定
- マイナビへアクセス
- マイナビにて企業詳細URLを取得
- Webdriverを閉じる
import os
import csv
import requests
from bs4 import BeautifulSoup
from selenium import webdriver
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.common.by import By
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.chrome.options import Options
import time
from datetime import datetime as dt
import traceback
# キーワード入力
search_word = input("業種キーワード=")
# 作成日のフォルダとファイル作成
today = dt.now()
folder_name = today.strftime('%Y-%m-%d')
os.makedirs(folder_name, exist_ok=True)
# CSVファイル生成
csv_file_path = os.path.join(folder_name, f'{search_word}.csv')
with open(csv_file_path, 'w', newline='', encoding='utf8') as csv_file:
csv_writer = csv.writer(csv_file)
csv_writer.writerow(['会社名', '住所', '電話番号'])
# Chromedriverの設定
options = Options()
options.add_argument('--headless')
driver = webdriver.Chrome(r"path/to/driver", options=options)
# マイナビ
url = f'https://job.mynavi.jp/24/pc/corpinfo/searchCorpListByGenCond/index?actionMode=searchFw&srchWord={search_word}&q={search_word}&SC=corp'
driver.get(url)
# 企業詳細URL格納リスト
company_urls = []
# 企業の詳細URLの取得
while True:
company_list = WebDriverWait(driver, 10).until(EC.visibility_of_all_elements_located((By.CLASS_NAME, 'boxSearchresultEach')))
company_urls.extend([company.find_element_by_tag_name("a").get_attribute("href") for company in company_list])
try:
next_page = driver.find_element_by_xpath('//*[@id="lowerNextPage"]')
next_page.click()
time.sleep(3)
except:
traceback.print_exc()
break
driver.close()特定サイトにおける各ページURLのデータスクレイピング方法
- クローリングして取得した各詳細URLにアクセス
- 各詳細ページにてデータをスクレイピング
- 実行結果
for url in company_urls:
response = requests.get(url)
soup = BeautifulSoup(response.text, "html.parser")
try:
name = soup.select_one("#companyHead > div.heading1 > div > div > div.heading1-inner-left > h1").text
address = soup.select_one("#corpDescDtoListDescTitle50").text
number = soup.select_one("#corpDescDtoListDescText220").text
with open(csv_file_path, 'a', newline='', encoding='utf8') as csv_file:
csv_writer = csv.writer(csv_file)
csv_writer.writerow([name, address, number])
except:
print("next")全体コード
import os
import csv
import requests
from bs4 import BeautifulSoup
from selenium import webdriver
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.common.by import By
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.chrome.options import Options
import time
from datetime import datetime as dt
import traceback
# キーワード入力
search_word = input("業種キーワード=")
# 作成日のフォルダとファイル作成
today = dt.now()
folder_name = today.strftime('%Y-%m-%d')
os.makedirs(folder_name, exist_ok=True)
# CSVファイル生成
csv_file_path = os.path.join(folder_name, f'{search_word}.csv')
with open(csv_file_path, 'w', newline='', encoding='utf8') as csv_file:
csv_writer = csv.writer(csv_file)
csv_writer.writerow(['会社名', '住所', '電話番号'])
# Chromedriverの設定
options = Options()
options.add_argument('--headless')
driver = webdriver.Chrome(r"path/to/driver", options=options)
# マイナビ
url = f'https://job.mynavi.jp/24/pc/corpinfo/searchCorpListByGenCond/index?actionMode=searchFw&srchWord={search_word}&q={search_word}&SC=corp'
driver.get(url)
# 企業詳細URL格納リスト
company_urls = []
# 企業の詳細URLの取得
while True:
company_list = WebDriverWait(driver, 10).until(EC.visibility_of_all_elements_located((By.CLASS_NAME, 'boxSearchresultEach')))
company_urls.extend([company.find_element_by_tag_name("a").get_attribute("href") for company in company_list])
try:
next_page = driver.find_element_by_xpath('//*[@id="lowerNextPage"]')
next_page.click()
time.sleep(3)
except:
traceback.print_exc()
break
driver.close()
for url in company_urls:
response = requests.get(url)
soup = BeautifulSoup(response.text, "html.parser")
try:
name = soup.select_one("#companyHead > div.heading1 > div > div > div.heading1-inner-left > h1").text
address = soup.select_one("#corpDescDtoListDescTitle50").text
number = soup.select_one("#corpDescDtoListDescText220").text
with open(csv_file_path, 'a', newline='', encoding='utf8') as csv_file:
csv_writer = csv.writer(csv_file)
csv_writer.writerow([name, address, number])
except:
print("next")実行結果
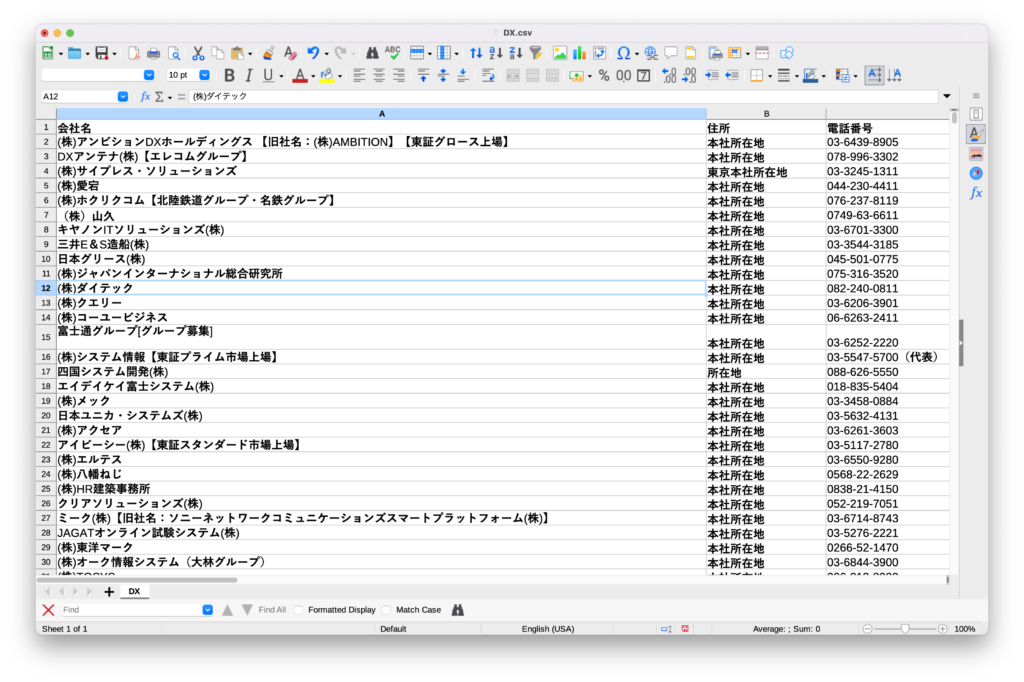
メールアドレスや別項目データも取得できる形が目指せるため、企業リスト案件ではマイナビを利用できると助かるケースが多いです。