これからPython学習を始めるにあたって、回り道せず効率的な勉強方法としてサンプルコードは有効です。
- Python学習ロードマップを具体的に知りたい
- Pythonの実行環境から整えたい
- 体系的なPython基礎学習のサンプルコードが見たい
- 各ライブラリやフレームワークのサンプルコード集を確認したい
上記の悩みを解決しながら、サンプルコードをもとにPythonを解説します。
また、各学習手順において必要な参考サイトや記事もまとめています。
▼【無料教材】Pythonを学びたい人へ資料を配布中▼
本記事をお読み頂いているプログラミング初学者向けに、本サイトはPythonを始めるためのガイドを配布しています。
以下に無料配布するPython資料をご紹介します。
- Python入門ガイド
- Python製デスクトップ用GUIライブラリガイド
- Python用学習ロードマップシート
- Tkinter製テンプレート集
- DXアイデア100選スライド
限られた時間を情報収集に極力かけず、他言語よりも「なぜ今Pythonを選ぶべきか」をガイドにしています。
プログラミングにおいて、情報収集の時間短縮は学習時間の短縮に直結します。
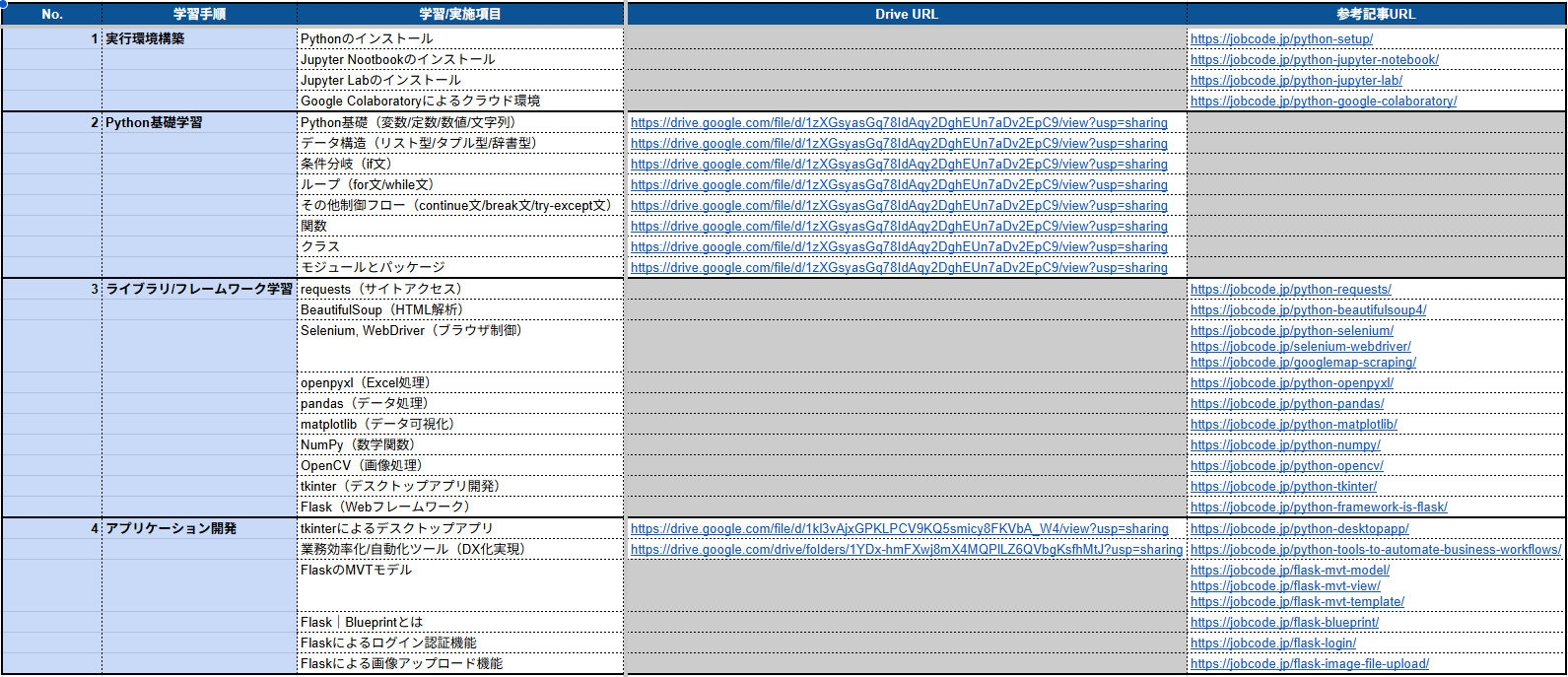
開発環境→基礎学習→ライブラリ/FW→アプリ開発に至る学習シートを配布しています。
また、定期アンケートによって「リアルな声」を反映して常に教材改善のアップデート情報を受け取れます。
\ メルアドのみで今すぐ受け取れます /
Python学習ロードマップによる具体的な学習手順
これからPython学習を始めるにあたって、回り道せず効率的なプログラミング学習を実施したい人は多いです。
Python学習において、学習手順を示すロードマップ化は必須です。
- 学習範囲の全体像を把握/理解
- 学習期間中の時間配分などに有効
以下は、学習手順を把握するためのPython学習ロードマップになります。
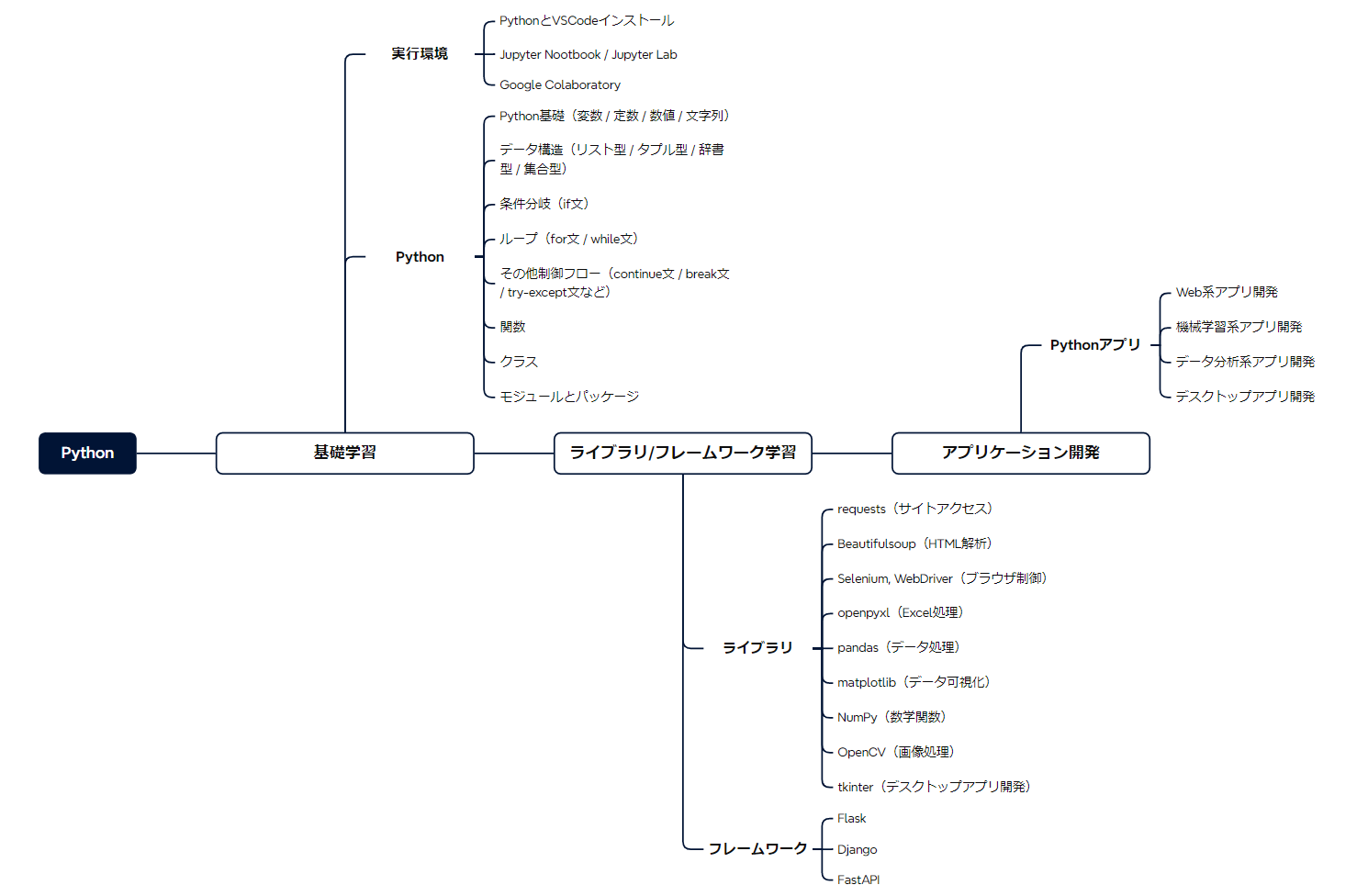
また、Python学習ロードマップで示した通り、学習の順番を間違えないよう注意しましょう。
開発環境構築からアプリ開発に至るまでの学習手順や無料サイト・無料教材情報を知りたい人は「【完全無料】Python学習ロードマップ|初心者向け教材と学習手順」を一読ください。
Python無料教材で完結する学習ロードマップ【初心者完全版】
本記事をお読み頂いているプログラミング初学者向けに、本サイトはPythonを始めるためのガイドを配布しています。
以下に無料配布するPython資料をご紹介します。
- Python入門ガイド
- Python製デスクトップ用GUIライブラリガイド
- Python用学習ロードマップシート
- Tkinter製テンプレート集
- DXアイデア100選スライド
- Python関連のメルマガ情報
- 定期アンケートによる教材強化
これからPython学習を始めたい人へ、Pythonを学ぶメリットや学習ロードマップ用シートを用意しています。
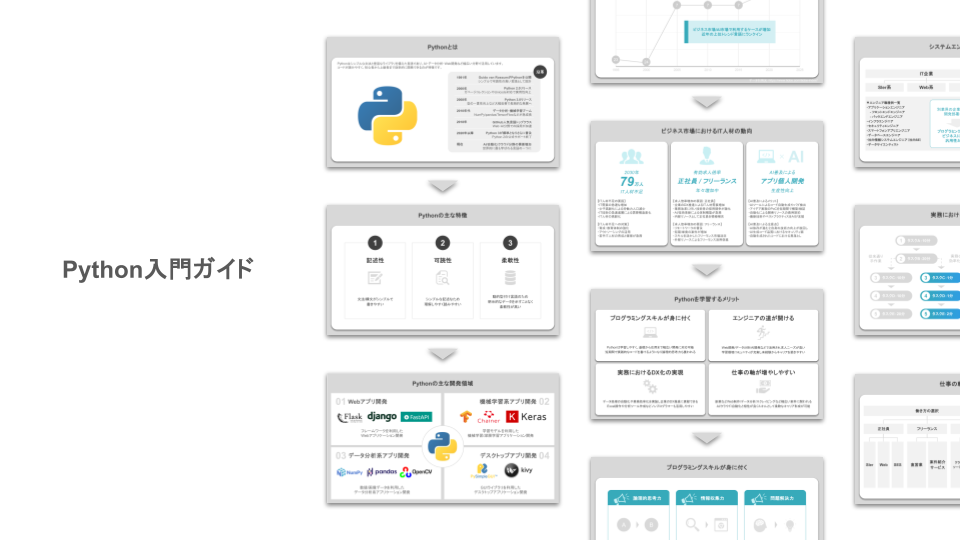



Python入門ガイドの概要

Python入門ガイドは、Python初学者向けに市場の動向や今後のプログラミングのヒントをまとめた資料になります。
以下は、Python入門ガイドの目次になります。(大枠のみ記載)
- Pythonとは
- Pythonの動向
- Pythonを学習するメリット
- Pythonからプログラミングを始める
上記の目次から、Pythonの特徴/開発領域/ビジネス市場の動向/仕事幅の増やし方など様々な観点で図解化しています。
Python製デスクトップ用GUIライブラリガイドの概要

本ガイドは、Pythonでデスクトップアプリを開発する際の基本的な概念から解説した資料になります。
特に、標準ライブラリであるtkinter、拡張版であるttk、モダンなデザインを可能にするttkbootstrapの比較と活用方法までを体系的にまとめたガイドです。
以下は、Python製デスクトップ用GUIライブラリガイドの目次になります。(大枠のみ記載)
- ライブラリとフレームワークの基礎
- GUIライブラリの比較(tkinter / ttk / ttkbootstrap)
- 実装の基本:配置とウィジェット
- ttkbootstrapのテーマデザイン
Pythonで「実用的で見た目の良いツール」を作りたい方にとってのロードマップになっています。
DXアイデア100選スライドの概要

本ガイドは、Pythonを活用して「誰でもできる作業」を自動化する具体的なアイデアをまとめた資料になります。
以下は、DXアイデア100選スライドの目次になります。(大枠のみ記載)
- 導入:賢い働き方へのシフト
- 実務に直結する自動化アイデア集
– Excel・ドキュメント作成|20選
– Web情報収集・リサーチ|20選
– コミュニケーション・通知|20選
– ブラウザ操作・システム連携|20選
– デスクトップアプリ・AIツール活用|20選 - 付加価値の創出
単なる技術解説ではなく「人生をどうハックするか」といった視点で、業務効率化による時間創出のヒントになるアイデア集になります 。
限られた時間を情報収集に極力かけず、他言語よりも「なぜ今Pythonを選ぶべきか」をガイドにしています。
プログラミングにおいて、情報収集の時間短縮は学習時間の短縮に直結します。
開発環境→基礎学習→ライブラリ/FW→アプリ開発に至る学習シートを配布しています。
また、定期アンケートによって「リアルな声」を反映して常に教材改善のアップデート情報を受け取れます。
\ メルアドのみで今すぐ受け取れます /
Pythonの実行方法
ここでは、2種類のPython実行方法を解説します。
| 実行方法 | 概要 |
|---|---|
| インタープリタの起動 | 実行結果を1つずつ確認しながらプログラムを実行 |
| Pythonファイルの実行 | プログラムを書いたファイルを指定して実行 |
インタープリタの起動
簡易的なプログラムを試す場合は、インタープリタといった方法でPythonを実行するのが便利です。
Pythonのプログラムの実行結果を1つずつ確認しながらプログラムを実行できるのが特徴になります。
インタープリタを起動するには、VSCodeのターミナルで以下のようにコマンドを実行してください。
Windowsならpythonコマンド、macOSならpython3コマンドを実行してください。
「>>>」が表示されればインタープリタが起動しています。
> python
>>>% python3
>>>インタープリタを終了するには、「exit()」とコマンドを入力してからEnterキーを押してください。
Pythonファイルの実行
一定の長さを持つプログラムや何度も実行するようなプログラムは、インタープリタによる実行は向いていません。
そこでプログラムを書いたファイルを指定して実行する方法があります。
Windowsの場合はVSCodeのターミナル上で「python < ファイル名>」、macOSの場合は「python3 <ファイル名>」と入力してプログラムファイルを実行します。
> python sample.py% python3 sample.pyディレクトリ以外の場所で実行する場合は、パス付きでファイル名を指定してください。
Pythonプログラムの基本構造
Pythonには、基本的な構文ルールが存在します。
以下は、Pythonプログラムを記述する際に「必ず守るべき」構造上のルールです。
| ルール | 説明 | ポイント |
|---|---|---|
| インデント | ブロックの内部は半角スペース4つで字下げ | スペースとタブを混ぜないこと |
| コロン( : ) | 制御構文の行末に付ける | コロンの後は必ずインデントが続く |
| 文の終わり | セミコロンは不要.1行に複数文書くときのみ使用可能 | 原則1行に1文が推奨 |
| コメント | コメントは#から始める.文末にも書ける | 説明が必要な箇所には積極的に使うこと |
| 関数定義 | def 関数名(引数): で始め内部をインデントで構成 | 定義と処理ブロックは一続きにする |
| クラス定義 | class クラス名: で始め内部に__init__などの関数を定義 | インデントの入れ子に注意 |
| 空行 | 複数の関数やクラスの間には空行を1〜2行入れる | コードの可読性が大きく向上する |
| 変数名/定数名 | 通常はスネークケース(snake_case)を使う | クラスはキャメルケース(CamelCase) |
def greet(name): # 関数定義とコメント
if name: # 条件文とコロン
print(f"Hello, {name}") # インデントされた処理
else:
print("Hello, stranger")- インデントは構文の一部である(4スペースが標準)
- コロン(:)が付く行の後には必ずインデントされたブロックが続く
- 波かっこは使わない(C言語系と違う点)
- コメントや空行で可読性を高める
- 関数・変数の命名規則も大事(snake_case vs CamelCase)
さらに詳しく学びたい場合は、PEP 8(Pythonの公式スタイルガイド)もおすすめです。
Pythonの基礎|サンプルコード集
Pythonの勉強において、当然ながら基礎内容は必須になります。
特に、その他プログラミング言語にも共通する基礎内容は、プログラミング思考を養うのにも有益です。
- Pythonの基本(変数,定数,数値,文字列など)
- コレクション(リスト型,タプル型,辞書型)
- 条件分岐(if文)
- ループ(for文,while文)
- 関数
- クラス
- モジュールとパッケージ
プログラミング言語Pythonにおいて、最低限の基礎知識を解説します。
さらに詳しく知りたい・理解したいという方は「Python3 公式ドキュメント」を参照してください。
詳細な仕様とコーディング例を確認できます。
Pythonは海外発祥のプログラミング言語になりますが、公式ドキュメントは日本語に翻訳されているため読みやすく設計されています。

Pythonの基本(変数,定数,数値,文字列など)
Pythonに限らず、プログラムを扱う際に以下の基本データ型を理解する必要があります。
| 基本データ型 | 概要 |
|---|---|
| 文字列データ | ‘’, “”によって括られたデータは文字列型として認識される |
| 数値データ | 整数(int), 小数(float)として認識される |
文字列データ
ここでは、基本的な文字列データの扱い方を解説します。
| 文字列データの扱い方 | 概要 |
|---|---|
| 文字列の生成 | 文字列リテラル(例: “Hello”)を使って新しい文字列を作成 |
| 文字列への型変換 | str()関数を使って数値や他の型を文字列に変換 |
| 文字列の連結と繰り返し | +演算子で文字列を結合し、*演算子で指定回数だけ繰り返す |
| 文字列の抽出 | インデックス(例: s[0])やスライス(例: s[1:4])で部分文字列を取得 |
| 文字列の書式設定 | f文字列(例: f”{name}さん”)やformat()メソッドを使用 |
文字列の生成
シングルクォーテーション「”」またはダブルクォーテーション「””」で括られた文字列は文字列型として認識されます。
Python 3系はUnicodeを標準でサポートしているので日本語も使えます。
moji = 'Python'
kazu = "123"数値に関しても、シングルあるいはダブルクォーテーションで括ることによって文字列データと認識されます。
文字列の型変換
str関数を使うことで他の型から文字列型に変換できます。
次の例では数値を文字列型に変換しています。
>>> str(10)
'10'文字列の連結と繰り返し
「+」演算子を使うことで文字列を連結し1つの文字列にすることができます。
>>> 'あいうえお' + 'かきくけこ'
'あいうえおかきくけこ'「*」演算子で文字列を繰り返すこともできます。
>>> 'あいうえお' * 2
'あいうえおあいうえお'文字列の抽出
文字列の後ろに角括弧([ ])を付けることで文字列内の文字を抽出できます。
1文字だけ抽出したい場合は、左から0、1、… と数えて何番目の文字を抽出するかを角括弧内に書きます。
右から数える場合は、-1、-2、… と数えます。
>>> 'あいうえお'[1]
'い'
>>> 'あいうえお'[-1]
'お'複数の文字を抽出する場合は、[開始位置 :終了位置 : ステップ数]を指定します。
開始位置は1文字の抽出のときと同様に数えます。
終了位置も数え方は一緒ですが、抽出されるのは指定した位置より1つ手前の文字までなので注意が必要です。
ステップ数で指定数だけスキップしながら文字を抽出することもできます。
>>> 'あいうえお'[:]
'あいうえお'
>>> 'あいうえお'[:2]
'あい'
>>> 'あいうえお'[2:]
'うえお'
>>> 'あいうえお'[2:4]
'うえ'
>>> 'あいうえお'[::2]
'あうお'
>>> 'あいうえお'[1:4:2]
'いえ'文字列の書式設定
formatメソッドを使って値を文字列に埋め込むことができます。
具体的な用途としては、メールの書式(format)を決めておいて値を動的に埋め込むときなどに使えます。
以下の例では、文字「Job」と「Code」を埋め込んでから出力します。
Python 3.6以降では、文字列の中に値を直接埋め込むことができる「f-string」という方法も使えます。
本記事では利用しないため説明は割愛しますが、詳しく知りたい方はPython公式サイトをご覧ください。
>>> a='Job'
>>> b='Code'
>>> '{}, {}'.format(a, b)
'Job, Code'
>>> '{1}, {0}'.format(a, b)
'Code, Job'
>>> '{arg1}, {arg2}'.format(arg1=b, arg2=a)
'Code, Job'
数値データ
ここでは、基本的な数値データの扱い方を解説します。
| 数値データの扱い方 | 概要 |
|---|---|
| 数値への型変換 | 数値データをint↔floatへ型変換する |
数値への型変換
文字列の時と同様にint()関数とfloat()関数を使うことで、int及びfloatに他の型から型変換できます。
以下は文字列からintまたはfloat型へ型変換した例です。
>>> int('10')
10
>>> float('10.2')
10.2Python3の整数と小数はそれぞれintとfloatという型で扱います。
「10」や「10.2」とすれば前者はint、後者はfloatと自動で解釈してくれます。
算術演算では表の算術演算子を使うことができます。
| 演算子 | 用途 | 例 |
|---|---|---|
| + | 加算 | 4 + 2 = 6 |
| – | 減算 | 4 – 2 = 2 |
| * | 乗算 | 4 * 2 = 8 |
| / | 除算(計算結果はfloat型) | 4 / 2 = 2.0 |
| // | 除算(計算結果はint型,小数点以下切り捨て) | 4 // 2 = 2 |
| % | 剰余 | 4 % 2 = 0 |
| ** | 累乗 | 4 ** 2 = 16 |
ブール値
Pythonでは、真偽を表すためにブール値といったデータ型を提供してます。
例えば、2つの数値を比較するとPythonは結果をブール値として返します。
bool()関数にて、問われる値が「真」であればTrue、「偽」であればFalseを返します。
x = 20
y = 10
result = x > y
print(result)
# 出力:True
result = x < y
print(result)
# 出力:Falsebool()関数にて、問われる値が「真」であればTrue、「偽」であればFalseを返します。
result = bool('Hi')
print(result)
# 出力:True
result = bool(100)
print(result)
# 出力:True
result = bool(0)
print(result)
# 出力:False以下は Pythonにおける偽値です。
- 数字のゼロ (0)
- 空の文字列 ””
- False
- None
- 空のリスト []
- 空のタプル ()
- 空の辞書 {}
定数
定数は変数と異なり、プログラム実行中に値は変化しません。
Pythonは残念ながら定数をサポートしていません。
これを回避するために変数名を全て大文字にし、変数を定数として扱います。
# 円周率
PI = 3.141592このような変数に遭遇した場合、値を変更しないでください。
これらの変数は規則ではなく慣例により定数とされています。
コレクション(リスト型,タプル型,辞書型)
コレクションとは、データをまとめて管理できるデータ型のことです。
ここでは、基本的なコレクションの扱い方を解説します。
| コレクション名 | 概要 |
|---|---|
| リスト(list) | 順序があるデータの並びを表すコレクション |
| タプル(tuple) | リスト同様、順序があるデータの並びを表すコレクション |
| 辞書(dictionary) | キーと値をセットにしてデータを管理するコレクション |
各コレクションの扱い方を理解していきましょう。
リスト
ここでは、基本的なリストデータの扱い方を解説します。
| リストデータの扱い方 | 概要 |
|---|---|
| リストの生成 | 角括弧([ ])内にカンマ(,)でリスト生成 |
| リストへの型変換 | 他の型からリストに型変換 |
| 要素の抽出 | 角括弧([ ])を使って要素抽出 |
| 要素の書き換え | 角括弧([ ])を使って要素指定 |
リストの生成
角括弧([ ])内にカンマ(,)区切りでデータを並べるとリストを生成できます。
>>> ['あ', 'い', 'う', 'え', 'お']
['あ', 'い', 'う', 'え', 'お']リストへの型変換
list関数を使えば、他の型からリストに型変換できます。
次の例では文字列をリストに変換しています。
>>> list('あいうえお')
['あ', 'い', 'う', 'え', 'お']要素の抽出
リストは角括弧([ ])を使って要素を抽出できます。
特定のリストデータを抽出したい場合は、左から0、1、… と数えて何番目の文字を抽出するかを角括弧内に書きます。
右から数える場合は、-1、-2、… と数えます。
取り出し方は前述した「文字列の抽出」と同様です。
>>> a = ['あ', 'い', 'う', 'え', 'お']
>>> a[1]
'い'
>>> a[-1]
'お'
>>> a[1:4:2]
['い', 'え']要素の書き換え
角括弧([ ])を使って要素を指定して値を書き換えることができます。
>>> a = ['あ', 'い', 'う', 'え', 'お']
>>> a[4] = 'ん'
>>> a
['あ', 'い', 'う', 'え', 'ん']タプル
ここでは、基本的なタプルデータの扱い方を解説します。
| タプルデータの扱い方 | 概要 |
|---|---|
| タプルの生成 | 角括弧([ ])内にカンマ(,)でリスト生成 |
| タプルへの型変換 | 他の型からリストに型変換 |
| 要素の抽出 | 角括弧([ ])を使って要素抽出 |
タプルはリストと同じく、順序があるデータの並びを表すコレクションです。
ただし、タプルは要素を書き換えることができません。
定数の並びを表現するときなどに使えます。
タプルの生成
タプルはカンマ(,)区切りでデータを並べるだけで生成できます。
さらに、丸括弧「( )」を付けても同じようにタプルを生成できます。
丸括弧があったほうが紛らわしくないので付けておくことを推奨します。
>>> ('あ', 'い', 'う', 'え', 'お')
('あ', 'い', 'う', 'え', 'お')タプルへの型変換
tuple関数を使ってリストをタプルに変換することができます。
>>> tuple(['あ', 'い', 'う', 'え', 'お'])
('あ', 'い', 'う', 'え', 'お')要素の抽出
リストと同じように角括弧([ ])を使って要素を抽出することができます。
>>> a = ('あ', 'い', 'う', 'え', 'お')
>>> a[1]
'い'
>>> a[-1]
'お'
>>> a[1:4:2]
('い', 'え')辞書
ここでは、基本的な辞書データの扱い方を解説します。
| 辞書データの扱い方 | 概要 |
|---|---|
| 辞書の生成 | 波括弧({ })の中に「キー: 値」のセットをカンマ(,)区切りで辞書生成 |
| 要素の抽出 | getメソッドでキーを指定して値取得 |
| 要素の追加と書き換え | 存在しないキーを指定して要素追加, 存在するキーを指定して値書き換え |
辞書はキーと値をセットにしてデータを管理するコレクションです。
リストやタプルと違ってデータに順序はなく、データの書き換えが可能なコレクションとなります。
辞書の生成
波括弧({ })の中に「キー: 値」のセットをカンマ(,)区切りで並べると辞書を生成できます。
>>> {'a': 'あ', 'b': 'い', 'c': 'う', 'd': 'え', 'e': 'お'}
{'a': 'あ', 'b': 'い', 'c': 'う', 'd': 'え', 'e': 'お'}要素の抽出
要素は角括弧([ ])かgetメソッドでキーを指定すれば値を取得できます。
角括弧を使った場合、存在しないキーを指定するとエラーになります。
getメソッドを使う場合は、第2引数にキーが存在しない場合の出力値を設定できます。
第2引数を指定しなくてもエラーになるのではなくNoneが返ってきます。(画面上には何も表示されません)
>>> data = {'a': 'あ', 'b': 'い', 'c': 'う', 'd': 'え', 'e': 'お'}
>>> data['b']
'い'
>>> data.get('b')
'い'
>>> data['f']
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
KeyError: 'f'
>>> data.get('f', 'nothing')
'nothing'
>>> data.get('f')
>>>要素の追加と書き換え
存在しないキーを指定して代入操作をすると、要素を追加できます。
存在するキーを指定して代入操作をすると、値の書き換えができます。
>>> data = {'a': 'あ', 'b': 'い', 'c': 'う', 'd': 'え', 'e': 'お'}
>>> data['f'] = 'か'
>>> data
{'a': 'あ', 'b': 'い', 'c': 'う', 'd': 'え', 'e': 'お', 'f': 'か'}
>>> data['f'] = 'ん'
>>> data
{'a': 'あ', 'b': 'い', 'c': 'う', 'd': 'え', 'e': 'お', 'f': 'ん'}条件分岐(if文)
ifやelifのあとにTrue(真)またはFalse(偽)となる式や値を記述すると処理を分岐できます。
ifやelifの文末にコロン(:)が必要です。
実例では、xが ‘Job’ でも’Code’ でもなければelseのprint関数が実行されます。
==は比較演算子の一種で、比較演算子にはその他に表のようなものがあります。
また、論理演算子も分岐条件の判定に用いられます。
if x == 'Job':
print('Job')
elif x == 'Code':
print('Code')
else:
print('not Job Code')| 比較演算子 | 意味 | 使用例 |
|---|---|---|
| == | 等号 | >>> ‘あ’ == ‘あ’ True |
| != | 等号否定 | >>> ‘あ’ != ‘あ’ False |
| >, >=, <, <= | 不等号 | >>> 1 < 5 True |
| in | 要素に存在するか | >>> ‘あ’ in [‘あ’, ‘い’, ‘う’] True |
| 論理演算子 | 意味 | 使用例 |
|---|---|---|
| and | 論理積 | >>> True and False False |
| or | 論理和 | >>> True or False True |
| not | 否定 | >>> not True False |
ループ(for文,while文)
ここでは、基本的なループの扱い方を解説します。
| ループの種類 | 概要 |
|---|---|
| for文 | 指定回数などによるループ |
| while文 | 条件による無限ループ |
for文
実例では、forを使ったループの例を示しており実行結果も載せています。
range関数は数値のシーケンスを作り出すことができ、使い方は以下の通りです。
- range(開始数値, 終了数値, スキップ数)
- 終了数値のみ必須
- 開始数値を省略した場合は0から開始
- スキップ数を2とすると1の次は3となる
- 終了数値1つ前の数値が取り出される
実例では、1から5までの数値が順番に変数iに格納されループします。
このように「for … in …」という書き方はPythonの書き方でよく使われます。
range関数の他にもリストやタプルや辞書などでもループを回せます。
また、辞書の場合はキーが取り出されることになります。
breakとcontinueはループ制御に使われていますが、breakはループから抜け出す命令でcontinueは次のループ処理に移る命令になります。
for i in range(1, 6):
if i == 2:
print(i, ' if')
elif i == 4:
print(i, ' elif')
break
else:
print(i, ' else')
continue上記のプログラムを実行すると次の実行結果になります。
1 else
2 if
3 else
4 elifwhile文
whileを使ったループも記述することができます。
whileは後ろに書いた条件が満たされる限りループするため「while True:」と書いて無限ループを作ることができます。
以下の例では「i += 1」と書いてありますが、これは変数iを1増やす命令です。
他のプログラミング言語に見られる「i++」という書き方はできないので注意してください。
i = 1
while True:
print(i)
i += 1
if i == 5:
break上記のプログラムを実行すると次の実行結果になります。
1
2
3
4関数
Pythonの関数定義は「def」からはじまり、半角スペースを入れてから関数名を書きます。
def <関数名>():
使用例での関数定義の引数では「arg3=’baz’」としています。
これは関数呼び出しでarg3を指定しなくてもデフォルトでarg3の引数に「’baz’」を設定してくれる書き方となっています。
関数呼び出しでは引数名を指定(arg2=’bar’)することができますが(キーワード引数と呼びます)、引数名なしの指定(使用例では「’foo’」。位置引数と呼びます)をすべて書き終わったあとに書かなければならない点に注意が必要です。
# 関数定義
def func_name(arg1, arg2, arg3='baz'):
print(arg1, arg2, arg3)
# 関数呼び出し
func_name('foo', 'bar') # foo bar baz
func_name('foo', arg2='bar', arg3='qux') # foo bar qux引数の書き方で「*<引数名>」と「**<引数名>」はDjangoでもよく見られる形です。
前者は位置引数であふれた引数を1つのタプルにまとめる働きをします。
後者はキーワード引数を1つの辞書にまとめる働きをします。
なお、引数名は「args」と「kwargs」という名前でなくてもよいのですが、慣例でこの名前がよく使われます。
# 関数定義
def func_name(arg, *args, **kwargs):
print(arg, args, kwargs)
# 関数呼び出し
func_name('foo', 'bar', 'baz', a='qux', b='quux') # foo ('bar', 'baz') {'a': 'qux', 'b': 'quux'}再帰関数
再帰とは、「ある関数が自分自身を呼び出す」ことで問題を小さく分割して解く手法です。
直感的には「入れ子(ネスト)になった問題を一つずつ外側から処理していく」イメージです。
数学でいう帰納法(数学的帰納法)と考え方が似ています。
再帰関数を作るときは次の4ステップを意識します。
- 最小ケース(base case)を決める
- 問題を小さくする(再帰ケース)
- 呼び出しが必ず最小ケースに近づくようにする
- 再帰呼び出しが正しいと仮定して全体を組み立てる(帰納的思考)
以下は、階乗(factorial)を利用した最も基本的な例になります。
0! = 1
n! = n × (n−1)! (n > 0)
# 階乗を計算する再帰関数
def factorial(n):
if n <= 1:
return 1
return n * factorial(n - 1)
# 実行例
print(factorial(1)) # 1 の階乗 -> 1
print(factorial(3)) # 3 の階乗 -> 6
print(factorial(5)) # 5 の階乗 -> 120呼び出し時と戻り時を print で表示する「デバッグ版」を記載しておきます。
def factorial_debug(n, depth=0):
indent = " " * depth # ネストの深さに応じてインデント
print(f"{indent}→ factorial({n}) を呼び出し")
if n <= 1:
print(f"{indent} 基本ケース: {n} <= 1 なので 1 を返す")
return 1
# 再帰呼び出し(次の深さへ)
result_sub = factorial_debug(n - 1, depth + 1)
result = n * result_sub
print(f"{indent}← factorial({n}) の計算: {n} * {result_sub} = {result}")
return result
# 実行例
print("最終結果 =", factorial_debug(5))→ factorial(5) を呼び出し
→ factorial(4) を呼び出し
→ factorial(3) を呼び出し
→ factorial(2) を呼び出し
→ factorial(1) を呼び出し
基本ケース: 1 <= 1 なので 1 を返す
← factorial(2) の計算: 2 * 1 = 2
← factorial(3) の計算: 3 * 2 = 6
← factorial(4) の計算: 4 * 6 = 24
← factorial(5) の計算: 5 * 24 = 120
最終結果 = 120- → は「呼び出されたとき」
- ← は「戻って計算結果が出たとき」
- depth 引数を使いインデントを付け、再帰の深さを目で追いやすくしている。
- 最後に 最終結果 = 120 が出力され、5! の計算過程を可視化。
ラムダ式
Pythonはラムダ式を使用すると、無名関数を定義できます。
無名関数は、一度だけ使う必要がある場合に便利です。
lambda 引数: 式
lambda の後に引数を書いて、: の右側に1つの式を書きます。
式の評価結果がその関数の戻り値になります。
文(statement)を含められない(例:return, if: 節のような複数行の処理、代入などは不可。ただし条件式 a if cond else b は使える)。
# ラムダ(無名関数)を変数に代入
square = lambda x: x * x
# def で書いた場合(同等の処理)
def square_def(x):
return x * x
print(square(4)) # => 16
print(square_def(4)) # => 16lambda(短く書ける利点)と def はどちらも関数オブジェクトを作ります。
クラス
クラスを定義するには以下のように書きます。
丸括弧「( )」の中に親クラスを書いて継承を定義することもできます。
class <クラス名>():
クラス変数は①のように「<クラス変数名> =」で定義でき、インスタンス変数は通常__init__メソッド(コンストラクタ)の中で③のように「self.<インスタンス変数名> =」で定義します。
クラス変数とインスタンス変数の呼び出しはそれぞれ「<クラス名>.<クラス変数名>」(②)、「self.<インスタンス変数名>」(④)のように行います。
メソッドは「def <メソッド名>(self):」で定義できます。
第1引数は必ず自身のインスタンスを表すselfと決まっています。
ほかの引数はselfに続けてカンマ(,)区切りで記述します。
例えば「def <メソッド名>(self, <引数1>, <引数2>)」のように書きます。
親クラスのメソッドは子クラスでオーバーライドできますが、オーバーライドした子クラスのメソッドを呼び出しても親クラスのメソッドは見えなくなってしまいます(⑥)。
なお、子クラスから親クラスのメソッドを使いたい場合は、super()を使って呼び出すことはできます(⑤)。
# 親クラス
class Parent():
# クラス変数の設定
var_class = 'parent' ①
# 親子共通メソッド
def method_common(self):
print('method_common ' + Parent.var_class) ②
# 親クラスの独自メソッド
def method_parent(self):
print('method ' + Parent.var_class)
# 子クラス
class Child(Parent):
# コンストラクタ
def __init__(self, value):
# インスタンス変数の設定
self.var_instance = value ③
# 親子共通メソッドのオーバーライド
def method_common(self):
print('method_common ' + self.var_instance) ④
# 子クラスの独自メソッド
def method_child(self):
print('method ' + self.var_instance)
super().method_parent() ⑤
if __name__ == '__main__':
# 子クラスのインスタンス化
child = Child('child')
# オーバーライドしたメソッドを呼び出して出力値を確認
child.method_common() # 出力 => method_common child 6
# 子クラスの独自メソッドから親クラスのメソッドを呼び出して出力値を確認
child.method_child() # 出力 => method_child / method_parent
# 子クラスには定義していない親クラスのメソッドを呼び出して出力値を確認
child.method_parent() # 出力 => method_parentコンストラクタは、オブジェクトが生成される時に実行されるメソッド(関数)
オブジェクトが扱う変数などの初期化を行います。
「親クラス」で定義されたインスタンスメソッドを継承した「子クラス」で独自に定義し直して上書きすることを指します。
「子クラス」で機能を追加する必要がある場合などにオーバーライドを利用します。
モジュールとパッケージ
関数やクラスをまとめたPythonファイル(拡張子は.py)のことを「モジュール」と呼びます。
そして、このモジュールを束ねて__init__.pyファイルを含んだディレクトリをパッケージと呼びます。
モジュールは他のパッケージにあるモジュールを読み込んで利用することができます。
例えば、図のような構成になっているとします。
├── import_test.py
└── package
├── __init__.py
└── module.pyimport_test.pyからmodule.pyに定義した関数(func)を利用するには、次の3通りの方法があります。
1. import <パッケージ名>.<モジュール名>
2. from <パッケージ名> import <モジュール名>
3. from <パッケージ名>.<モジュール名> import <オブジェクト名>(<関数名など >)
import package.module
package.module.func() #関数を呼び出しfrom package import module
module.func() #関数を呼び出しfrom package.module import func
func() #関数を呼び出しそれぞれの例で関数の呼び出し方が違う点に注意しましょう。
マルチスレッド
マルチスレッドは、一つのプログラム(プロセス)の中で複数の処理の流れを同時に実行するための仕組みです。
特にI/O(ファイルの読み書きやネットワーク通信など)の待ち時間を有効活用し、プログラムの応答性を高めることができます。
ここでは、ネットワークからデータをダウンロードするような、I/O待ちが発生する処理をマルチスレッドで並行処理してみます。
Webサイトから2つの情報をダウンロードする処理を模倣し、それぞれに時間がかかる状況を再現します。
import threading
import time
import requests
# 各スレッドで実行される関数
def download_data(url, thread_name):
"""
指定されたURLからデータをダウンロードする処理を模倣する関数
"""
print(f"[{thread_name}] ダウンロード開始: {url}")
# ネットワーク通信(I/O待ち)を模倣
try:
response = requests.get(url)
print(f"[{thread_name}] {url} のダウンロード完了 (ステータスコード: {response.status_code})")
except requests.exceptions.RequestException as e:
print(f"[{thread_name}] エラー: {e}")
# ここでは仮に2秒の処理時間を追加
time.sleep(2)
print(f"[{thread_name}] データ処理完了")
if __name__ == "__main__":
urls = [
"https://www.google.com",
"https://www.wikipedia.org"
]
start_time = time.time()
# スレッドを格納するリスト
threads = []
# 各URLに対してスレッドを作成して開始する
for i, url in enumerate(urls):
thread_name = f"Thread-{i+1}"
# threading.Threadのインスタンスを作成
# target: スレッドで実行する関数
# args: その関数に渡す引数(タプルで指定)
thread = threading.Thread(target=download_data, args=(url, thread_name))
threads.append(thread)
thread.start() # スレッドの処理を開始
# 全てのスレッドが終了するのを待つ
for thread in threads:
thread.join()
end_time = time.time()
print("\nすべてのダウンロード処理が完了しました。")
print(f"実行時間: {end_time - start_time:.2f} 秒")以下はコードブロックごとに解説しています。
import threading
import time
import requeststhreadingはマルチスレッドを実現するPython標準ライブラリです。
timeは処理時間を計測するために使います。
requestsはWebサイトのアクセスに使う外部ライブラリです。
# 各スレッドで実行される関数
def download_data(url, thread_name):
"""
指定されたURLからデータをダウンロードする処理を模倣する関数
"""
print(f"[{thread_name}] ダウンロード開始: {url}")
# ネットワーク通信(I/O待ち)を模倣
try:
response = requests.get(url)
print(f"[{thread_name}] {url} のダウンロード完了 (ステータスコード: {response.status_code})")
except requests.exceptions.RequestException as e:
print(f"[{thread_name}] エラー: {e}")
# ここでは仮に2秒の処理時間を追加
time.sleep(2)
print(f"[{thread_name}] データ処理完了")download_data()関数は、各スレッドで実行される処理内容です。
requests.get(url) でWebサイトにアクセスします。
この間、サーバーからの応答を待つ「I/O待ち」が発生します。
CPUはこの待ち時間に別のスレッドの処理を進めることができます。
引数のthread_nameを表示することで、どのスレッドが動いているかを視覚的に確認できます。
if __name__ == "__main__":メインの処理を記述するブロックです。
# スレッドを格納するリスト
threads = []
# 各URLに対してスレッドを作成して開始する
for i, url in enumerate(urls):
thread_name = f"Thread-{i+1}"
# threading.Threadのインスタンスを作成
# target: スレッドで実行する関数
# args: その関数に渡す引数(タプルで指定)
thread = threading.Thread(target=download_data, args=(url, thread_name))
threads.append(thread)
thread.start() # スレッドの処理を開始threading.Threadクラスのインスタンスを作成することで、新しいスレッドを定義します。
target=download_dataで、スレッドに実行させたい関数を指定します。
args=(url, thread_name)で、その関数に渡す引数をタプル形式で指定します。
thread.start()を呼び出すと、スレッドがバックグラウンドで処理を開始します。
メインの処理はスレッドの終了を待たずにすぐに次のループに進みます。
# 全てのスレッドが終了するのを待つ
for thread in threads:
thread.join()
end_time = time.time()
print("\nすべてのダウンロード処理が完了しました。")
print(f"実行時間: {end_time - start_time:.2f} 秒")start() で開始した全てのスレッドの処理が終わるまで、メインの処理をここで待機させます。
これがないと、メインプログラムがスレッドの処理完了を待たずに終了してしまいます。
コードを実行すると、2つのダウンロード処理がほぼ同時に開始され、全体の実行時間は約2秒強になります。
もしシングルスレッドで順番に実行した場合、2秒 + 2秒 = 4秒 以上かかっていたはずです。
[Thread-1] ダウンロード開始: https://www.google.com
[Thread-2] ダウンロード開始: https://www.wikipedia.org
[Thread-1] https://www.google.com のダウンロード完了 (ステータスコード: 200)
[Thread-2] https://www.wikipedia.org のダウンロード完了 (ステータスコード: 200)
[Thread-1] データ処理完了
[Thread-2] データ処理完了
すべてのダウンロード処理が完了しました。
実行時間: 2.05 秒マルチスレッドは、ネットワーク通信やファイル操作のような待ち時間が多い処理を並行して行うことで、プログラム全体の実行時間を短縮し、効率を上げることができます。
マルチプロセス
マルチプロセスは、コンピュータに複数の作業を同時かつ独立して行わせる仕組みです。
時間がかかる処理を分割して並行で実行できるため、プログラム全体の処理時間を大幅に短縮できます。
ここでは、時間のかかる単純な計算をマルチプロセスで並列処理してみます。
0から9までの数字をそれぞれ2乗する計算を1秒ずつかけて行い、その結果を表示します。
import multiprocessing
import time
import os
# 各プロセスで実行される関数
def worker(num):
"""
受け取った数字を2乗し、どのプロセスが実行したかを表示する関数
"""
# どのプロセスIDで実行されているかを確認
process_id = os.getpid()
print(f"プロセスID: {process_id} が、{num} の計算を開始します。")
# 時間のかかる処理を模倣するために1秒待つ
time.sleep(1)
result = num * num
print(f"プロセスID: {process_id} の結果: {num} の2乗は {result} です。")
return result
if __name__ == "__main__":
# 処理対象のデータ
numbers = range(10) # [0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
# CPUのコア数を取得し、その数だけプロセスを生成する
# Poolを使うと、指定した数のプロセスをまとめて管理できる
with multiprocessing.Pool(processes=multiprocessing.cpu_count()) as pool:
print(f"利用可能なCPUコア数: {multiprocessing.cpu_count()} で処理を開始します。")
# pool.mapは、numbersの各要素をworker関数に渡し、並列処理を実行する
# 全てのプロセスの処理が終わるまで待機し、結果をリストで返す
results = pool.map(worker, numbers)
print("\nすべての処理が完了しました。")
print(f"最終的な結果リスト: {results}")以下はコードブロックごとに解説しています。
import multiprocessing
import time
import osmultiprocessingは、マルチプロセスを実現するPython標準ライブラリです。
timeは処理に時間をかけるためにtime.sleep()を使います。
osは、os.getpid()で現在実行中のプロセスのIDを取得できます。
どのプロセスがどの作業を担当しているかを確認できます。
# 各プロセスで実行される関数
def worker(num):
"""
受け取った数字を2乗し、どのプロセスが実行したかを表示する関数
"""
# どのプロセスIDで実行されているかを確認
process_id = os.getpid()
print(f"プロセスID: {process_id} が、{num} の計算を開始します。")
# 時間のかかる処理を模倣するために1秒待つ
time.sleep(1)
result = num * num
print(f"プロセスID: {process_id} の結果: {num} の2乗は {result} です。")
return resultworker()関数は、各プロセスで実際に実行される処理内容です。
引数で受け取ったnumを2乗して結果を返します。
os.getpid() でプロセスIDを表示することで、複数のプロセスが別々に動いていることを視覚的に確認できます。
if __name__ == "__main__":
# 処理対象のデータ
numbers = range(10) # [0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
# CPUのコア数を取得し、その数だけプロセスを生成する
# Poolを使うと、指定した数のプロセスをまとめて管理できる
with multiprocessing.Pool(processes=multiprocessing.cpu_count()) as pool:
print(f"利用可能なCPUコア数: {multiprocessing.cpu_count()} で処理を開始します。")
# pool.mapは、numbersの各要素をworker関数に渡し、並列処理を実行する
# 全てのプロセスの処理が終わるまで待機し、結果をリストで返す
results = pool.map(worker, numbers)
print("\nすべての処理が完了しました。")
print(f"最終的な結果リスト: {results}")Poolは、複数のプロセスをまとめて管理してくれる便利な機能です。
「プロセスのプール(たまり場)」を作っておき、タスクを投げ込むイメージです。
processes=multiprocessing.cpu_count() でコンピュータのCPUコア数を自動で取得し、その数だけプロセスを生成します。
map関数はnumbers というリスト([0, 1, 2, …]) の中身を一つずつ取り出し、worker 関数の引数として渡しそれぞれの処理を別々のプロセスに割り当てて同時に実行します。
全てのプロセスの処理が終わると、結果を results という一つのリストにまとめて返してくれます。
コードを実行すると、以下のように複数のプロセスIDがほぼ同時に処理を開始し、約1〜2秒で全ての計算が終わります(PCのコア数によります)。
シングルプロセスであれば、10秒かかっていたはずです。
利用可能なCPUコア数: 8 で処理を開始します。
プロセスID: 12345 が、0 の計算を開始します。
プロセスID: 12346 が、1 の計算を開始します。
プロセスID: 12347 が、2 の計算を開始します。
プロセスID: 12348 が、3 の計算を開始します。
...
プロセスID: 12345 の結果: 0 の2乗は 0 です。
プロセスID: 12346 の結果: 1 の2乗は 1 です。
...
すべての処理が完了しました。
最終的な結果リスト: [0, 1, 4, 9, 16, 25, 36, 49, 64, 81]マルチプロセスを使うことで、多くの処理を効率よく捌くことができます。
特に、動画処理や大規模なデータ分析など、重い処理を行う際に非常に強力な武器となります。
非同期処理
非同期処理は、一つの処理の流れ(スレッド)の中で待ち時間を活用して複数のタスクを効率的に切り替えながら進める仕組みです。
プログラム全体をブロックすることなく、多くの処理をスムーズに捌くことができます。
asyncioという標準ライブラリを使って非同期処理を実装するのが一般的です。
ここでは、3人の客(A, B, C)の注文を非同期で処理するカフェの店員をシミュレートします。
各注文には時間がかかる作業(コーヒーを淹れるなど)が含まれます。
# async def で定義された関数は「コルーチン」と呼ばれる
# これは中断・再開が可能な特別な関数
async def make_coffee(customer_name):
"""
コーヒーを淹れるのに3秒かかる処理を模倣するコルーチン
"""
print(f"{customer_name}さんのコーヒーを淹れ始めます。")
# asyncio.sleep() は非同期の待機処理。
# この待機中に、他のタスク(別の注文処理)に制御が移る。
await asyncio.sleep(3)
print(f"☕ {customer_name}さんのコーヒーができました!")
return f"{customer_name}さんのコーヒー"
async def main():
"""
メインの処理をまとめるコルーチン
"""
start_time = time.time()
# asyncio.gather() を使うと、複数のコルーチンをまとめて実行できる
# これにより、3人の客の注文が並行して処理される
results = await asyncio.gather(
make_coffee("A"),
make_coffee("B"),
make_coffee("C")
)
end_time = time.time()
print("\nすべての注文が完了しました。")
print(f"最終的な結果リスト: {results}")
print(f"実行時間: {end_time - start_time:.2f} 秒")
# 非同期処理のプログラムはここから実行される
if __name__ == "__main__":
asyncio.run(main())asyncioは、非同期処理を実現するPython標準ライブラリです。
関数の前に async を付けると、その関数はコルーチンになります。
コルーチンは、処理の途中で中断したり再開したりできる特別な関数で非同期処理の基本単位です。
await は「待つ」という意味で、時間のかかる処理(asyncio.sleep(3)など)の前につけます。
Pythonはawaitを見つけると処理が終わるのを待たずに一旦そのコルーチンの実行を中断し、実行可能な他のコルーチンに制御を移します。
待っていた処理が完了したら、中断した場所から処理を再開します。
asyncio.sleep()は、time.sleep() の非同期版です。
time.sleep()を使うとプログラム全体が停止してしまいますが、asyncio.sleep()は現在のタスクだけを待機させ、その間に他のタスクを実行させることができます。
asyncio.gather()は、複数のコルーチンをまとめて登録しそれらがすべて完了するまで並行して実行してくれます。
asyncio.run(main())は、async def で定義されたメインのコルーチン (main) を実行し、非同期処理のプログラム全体を開始するための命令です。
コードを実行すると、3人分のコーヒーの準備がほぼ同時に開始され、全体の処理は約3秒で完了します。
もし同期処理で順番に作っていたら、3秒 × 3人 = 9秒 かかっていたはずです。
Aさんのコーヒーを淹れ始めます。
Bさんのコーヒーを淹れ始めます。
Cさんのコーヒーを淹れ始めます。
(約3秒後)
☕ Aさんのコーヒーができました!
☕ Bさんのコーヒーができました!
☕ Cさんのコーヒーができました!
すべての注文が完了しました。
最終的な結果リスト: ["Aさんのコーヒー", "Bさんのコーヒー", "Cさんのコーヒー"]
実行時間: 3.01 秒非同期処理は、特にネットワーク通信やデータベースアクセスなど、I/Oの待ち時間が頻繁に発生するアプリケーション(Webサーバーなど)で非常に強力なパフォーマンスを発揮します。
Pythonにおけるエラー処理に関するサンプルコード集
Python学習を始めるにあたって、どうしても様々なパターンのエラーに出会います。
Pythonにおける一般的なエラー処理は、2種類に分けられます。
- 構文エラー(Syntax Error)
- 例外エラー(Exception)
Pythonによるエラー処理として、構文として誤っているものは「構文エラー」、構文として正しいが実行中に発生するエラーは例外と呼ばれます。
ここでは、Pythonにおける代表的なエラー一覧をまとめています。
| エラー名 | 概要 |
|---|---|
| SyntaxError | Python文法(Syntax)に誤りがある場合に発生 |
| NameError | 存在しない(定義されていない)変数名や関数名を使用した際に発生 |
| TypeError | 演算や関数が不適切な「型(Type)」のオブジェクトに対して実行された場合に発生 |
| ValueError | 関数の引数の「型」は正しいが、その「値(Value)」が不適切である場合に発生 |
| AttributeError | オブジェクトが持っていない属性(変数)やメソッド(関数)にアクセスした際に発生 |
| KeyError | 辞書(dict)において存在しないキー(Key)を指定し値を取得した際に発生 |
| ModuleNotFoundError | importしようとしたモジュールが見つからない場合に発生 |
| IndentationError | インデント(字下げ)が正しくない場合に発生 |
| IndexError | 範囲外のインデックス(添字)を指定して要素にアクセスした際に発生 |
| ZeroDivisionError | 数値をゼロ(0)で割ろうとした際に発生 |
Pythonのエラー処理に関するハンドリング集を確認したい人は「Pythonにおけるエラー処理とエラー一覧|例外処理のエラーハンドリング集」を一読ください。

Pythonの各ライブラリにおけるサンプルコード集
ここでは、Pythonで代表的なライブラリを用いたサンプルコード集(参考記事含む)を紹介します。
概要になりますが、詳細なプログラムの解説や部分的説明を求める人は、ぜひ関連記事から一読ください。
以下は、Pythonで代表的なライブラリのサンプルコード集になります。
- Seleniumのサンプルコード|クローリング&スクレイピング
- openpyxlのサンプルコード
- pandasのサンプルコード
- numpyのサンプルコード
- tkinterのサンプルコード
- fletのサンプルコード
特にメソッド関連は膨大な解説とサンプルコード集になるため、各ライブラリの記事をお読み頂けると幸いです。
Seleniumのサンプルコード|クローリング&スクレイピング
ここでは、以下の内容に関するSeleniumのサンプルコードをまとめます。
- SeleniumによるGoogleMapsスクレイピングプログラム
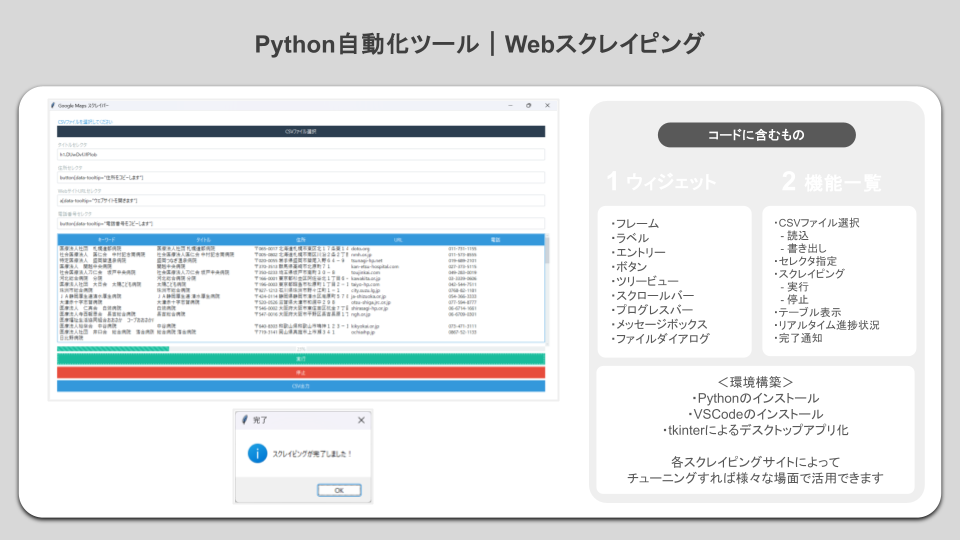
SeleniumによるGoogleMapsスクレイピングプログラム
ここから、SeleniumによるGoogleマップのスクレイピングプログラムについて解説します。
以下の流れでPythonプログラムを作成しています。
あくまで概要であり、各手順に対して詳細な作業内容を確認したい人は、「【Python】SeleniumによるGoogleマップのスクレイピング」を一読ください。
- 必要な各種ライブラリ
- Webdriverのセットアップ
- ブラウザ操作によるGoogleマップ検索結果
- 動的ページをスクロール
- 全データ表示後に各データをスクレイピング
- Seleniumによるスクレイピングプログラム実行結果
また、最終的に完成したサンプルコードが以下になります。
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.common.by import By
from selenium.webdriver.chrome.options import Options
import time
import csv
import traceback
def setup_driver():
options = Options()
options.headless = False
return webdriver.Chrome(r"/path/to/chromedriver", options=options)
def search_google_map(driver, search_word):
url = "https://www.google.co.jp/maps/"
driver.get(url)
time.sleep(3)
search_box = driver.find_element(By.ID, "searchboxinput")
search_box.send_keys(search_word)
time.sleep(1)
search_button = driver.find_element(By.XPATH, "//*[@id='searchbox-searchbutton']")
search_button.click()
time.sleep(3)
def scroll_to_bottom(driver):
while True:
before_count = len(driver.find_elements(By.CLASS_NAME, "m6QErb.DxyBCb.kA9KIf.dS8AEf.ecceSd .Nv2PK.THOPZb.CpccDe"))
scroll_elem = driver.find_element_by_xpath("/html/body/div[3]/div[9]/div[9]/div/div/div[1]/div[2]/div/div[1]/div/div/div[2]/div[1]")
for _ in range(3):
scroll_elem.send_keys(Keys.END)
time.sleep(1)
after_count = len(driver.find_elements(By.CLASS_NAME, "m6QErb.DxyBCb.kA9KIf.dS8AEf.ecceSd .Nv2PK.THOPZb.CpccDe"))
if before_count == after_count:
break
time.sleep(3)
def scrape_company_data(driver, search_word):
result_list = []
elems_1 = driver.find_element(By.CLASS_NAME, "m6QErb.DxyBCb.kA9KIf.dS8AEf.ecceSd")
elems_2 = elems_1.find_elements(By.CLASS_NAME, "Nv2PK.THOPZb.CpccDe")
for href in elems_2:
result_list.append(href.find_element(By.TAG_NAME, "a").get_attribute('href'))
for result in result_list:
try:
driver.get(result)
time.sleep(3)
company_name = driver.find_element(By.CLASS_NAME, "DUwDvf.fontHeadlineLarge").get_attribute('innerText')
address = driver.find_element(By.CLASS_NAME, "RcCsl.fVHpi.w4vB1d.NOE9ve.M0S7ae.AG25L").get_attribute('innerText')
with open(search_word + '.csv', 'a', newline='', encoding='utf8') as outcsv:
csvwriter = csv.writer(outcsv)
csvwriter.writerow([company_name, address])
except:
traceback.print_exc()
print("next")
def main():
search_word = "新宿 カフェ"
driver = setup_driver()
search_google_map(driver, search_word)
scroll_to_bottom(driver)
scrape_company_data(driver, search_word)
driver.quit()
if __name__ == "__main__":
main()サンプルコードを実行すると、以下のような結果が得られます。

また、以下はGUI操作を実現するためにtkinterを利用することで、デスクトップアプリ版も作成できます。
openpyxlのサンプルコード
ここでは、以下の内容に関するopenpyxlのサンプルコードをまとめます。
- openpyxlの各メソッド
- Excelデータのグラフ作成
- openpyxlを利用したデスクトップ用アプリ開発
openpyxlの各メソッド
openpyxlの各メソッドのサンプルコードは以下になります。
- openpyxlによるExcelファイルの基本操作
- ExcelファイルのRow(行), Column(列), Cell(セル)の取得・作成・削除
- openpyxl.workbook()
- openpyxl.worksheet()
- openpyxl.cell()
- openpyxl.styles()
- Chart
- Image
- Comment
各メソッドをサンプルコードを元に利用したい人は「【Python×Excel】openpyxlのインストール方法や使い方を徹底解説!」を一読ください。
Excelデータのグラフ作成
データ分析用として以下のExcelファイルを利用していきます。
- Excelファイル名:openpyxl_training.xlsx
- ワークシート名:youtube_DB
- 各データ項目名:公開日、タイトル、動画URL、再生回数、サムネURL、再生時間、いいね数、コメント数、動画説明

個人的に適当なファイルが見当たらなかったため、youtube動画のデータ分析で利用したファイルをもとに、グラフ作成用のサンプルコードを記載します。。
また、上記のExcelファイルは特定のYouTubeチャンネルに対してyoutube data APIを利用し、各動画データを取得しています。
import openpyxl
from openpyxl.chart import BarChart, Reference
# Excelファイルを読み込みます
wb = openpyxl.load_workbook('openpyxl_training.xlsx')
# ワークシートを取得します
ws = wb['youtube_DB']
# 公開日の列データを取得します
dates = [cell.value for cell in ws['A'][1:]]
# 再生回数の列データを取得します
views = [cell.value for cell in ws['D'][1:]]
# 新しいシートを作成します
chart_sheet = wb.create_sheet('グラフ')
# グラフを作成します
chart = BarChart()
chart.title = "再生回数と公開日の関係"
chart.x_axis.title = "公開日"
chart.y_axis.title = "再生回数"
# データ範囲を指定します
data = Reference(ws, min_col=4, min_row=2, max_col=4, max_row=len(views)+1)
categories = Reference(ws, min_col=1, min_row=2, max_row=len(dates)+1)
# データとカテゴリをグラフに追加します
chart.add_data(data, titles_from_data=True)
chart.set_categories(categories)
# グラフをシートに挿入します
chart_sheet.add_chart(chart, "A1")
# Excelファイルを保存します
wb.save('openpyxl_training.xlsx')実行結果から以下のグラフを得ることができました。

また、以下はGUI操作の実現にtkinterを利用することで、openpyxlを利用したデスクトップ用アプリ開発も可能です。
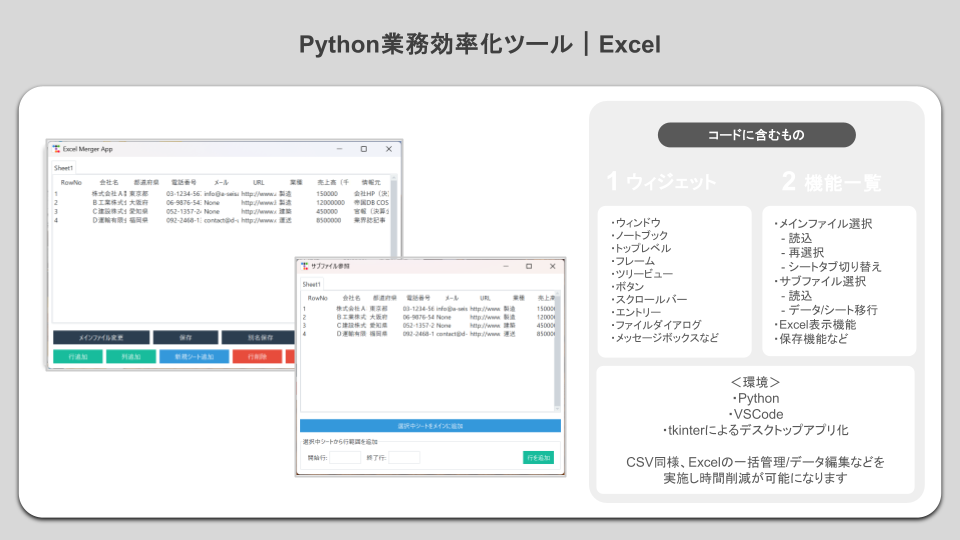
excel-merge-appの機能一覧
| 機能名 | 概要 |
|---|---|
| メインファイル選択 | 起動時/変更ボタンで対象のExcelファイルを選択しシートごとにタブ表示 |
| サブファイル参照 | 別ファイルを開きシートをタブ表示 |
| シート追加(新規シート) | 空のRowNo列のみを持つ新規シートを作成 |
| シート削除 | 選択中のタブ(シート)をメインノートブックから削除 |
| 行追加 | 選択中シートの選択行の直後または末尾に空行を挿入 |
| 行削除 | 選択中の行を削除しRowNoを再採番 |
| 列追加 | 選択中シートに新規列を追加し、既存行に空文字をパディング |
| 列削除 | RowNo以外の列から選択して削除し、既存データを再構築 |
| セル編集(ダブルクリック対応) | Treeview上のセルをダブルクリックで直接編集可能 |
| シートインポート(全シート) | サブファイルの選択中シートを丸ごとメインノートブックにコピー (データ含む) |
| シートインポート(行範囲指定) | サブファイルの選択中シートから開始/終了行を指定して複数行をメインシートに追加 |
| 保存・別名保存 | 編集結果を上書き保存または別名で保存 |
excel-merge-appで利用しているopenpyxlのメソッド一覧
| メソッド名 | 概要 |
|---|---|
| openpyxl.load_workbook(file_path, …) | 既存のExcelファイルを読み込んでWorkbookオブジェクトとして返す |
| openpyxl.Workbook() | 新規の空のExcelブックを作成 |
| wb.remove(ws) | 指定したワークシートをワークブックから削除 |
| wb.create_sheet(title=…) | 新しいワークシートをワークブックに追加 |
| ws.append(iterable) | ワークシートに1行分のデータを末尾に追記 |
| wb.save(file_path) | ワークブックを指定パスに保存 |
| ws.sheetnames | ワークブックに含まれるシート名のリストを返す |
| ws.iter_rows(min_row=…, values_only=True) | ワークシートの行をイテレータで返す |
| セル編集(ダブルクリック対応) | Treeview上のセルをダブルクリックで直接編集可能 |
| シートインポート(全シート) | サブファイルの選択中シートを丸ごとメインノートブックにコピー (データ含む) |
| シートインポート(行範囲指定) | サブファイルの選択中シートから開始/終了行を指定して複数行をメインシートに追加 |
| 保存・別名保存 | 編集結果を上書き保存または別名で保存 |
pandasのサンプルコード
ここでは、以下の内容に関するpandasのサンプルコードをまとめます。
- pandasの各メソッド
pandasの各メソッド
pandasの各メソッドのサンプルコードは以下になります。
- pandasのインポート方法
- list/dict/様々なデータ型のSeries作成
- Series作成時の名前追加とrename方法(カラム)
- DataFrameの列を抽出しSeriesを作成
- SeriesからDataFrameへの変換
- Seriesからデータの抽出方法(インデックス/条件指定/スライス)
- Seriesへのデータ(要素)の追加/削除/変更
- Seriesのインデックスを利用した演算
- Seriesのソート方法(sort_index/sort_values)
- Seriesの結合方法(concat)
- Seriesから統計情報の取得
- Seriesを使ったデータ分析例
- データの読み込みや全体像の把握
- データの状態を確認する(行数/列数/重複/選択的表示など)
- データ整形(データ型変更/列名変更/並び替えなど)
- データの欠損状態確認
- 値(欠損)の置き換えや削除
- DataFrameにおける集計
- DataFrameにおける可視化
- DataFrameにおける変数の前処理
- DataFrameによるデータの出力
特にpandasで利用される「Series」と「DataFrame」について解説してる「【Python】pandasとは?インストールやSeriesとDataFrameの使い方を解説」を一読ください。
例として、pandasのDataFrameを利用したCSVファイルデータ分析例を以下に記載します。
また、データ分析におけるデータ可視化を実施するためmatplotlibを活用します。
import pandas as pd
import matplotlib.pyplot as plt
# CSVの読み込みとSeriesの作成
df = pd.read_csv('sample_data.csv')
sales = df['Sales']
# データの先頭と末尾の表示
print("データの先頭3件:\n", sales.head(3))
'''
データの先頭3件:
0 150
1 200
2 300
Name: Sales, dtype: int64
'''
print("データの末尾3件:\n", sales.tail(3))
'''
データの末尾3件:
2 300
3 250
4 400
Name: Sales, dtype: int64
'''
# 基本統計量の表示
print("Seriesの統計情報:\n", sales.describe())
'''
Seriesの統計情報:
count 5.00000
mean 260.00000
std 96.17692
min 150.00000
25% 200.00000
50% 250.00000
75% 300.00000
max 400.00000
Name: Sales, dtype: float64
'''
# ヒストグラムの可視化
sales.hist(bins=5)
plt.xlabel('Sales')
plt.ylabel('Frequency')
plt.title('Sales Distribution')
plt.show()
# Seriesの結合による分析
discounts = df['Discount']
combined = pd.concat([sales, discounts], axis=1)
# 散布図による可視化
combined.plot(kind='scatter', x='Discount', y='Sales')
plt.title('Discount vs Sales')
plt.xlabel('Discount (%)')
plt.ylabel('Sales (Units)')
plt.grid(True)
plt.show()さらに詳しくpandasの利用方法を確認したい人は「【Python】pandasとは?インストールやSeriesとDataFrameの使い方を解説」を一読ください。

numpyのサンプルコード
ここでは、以下の内容に関するnumpyのサンプルコードをまとめます。
- numpyの代表的なメソッド
- numpyのその他メソッド
numpyの代表的なメソッド
numpyの代表的なメソッドのサンプルコードは以下になります。
- numpy.arange()
- numpy.array()
- numpy.dot()
- numpy.where()
- numpy.zeros()
データをお持ちでない人もサンプルデータを用意しているため、サンプルコードを確認してください。

numpyのその他メソッド
numpyのその他メソッドのサンプルコードは以下になります。
- numpy.ones()
- numpy.linspace()
- numpy.reshape()
- numpy.transpose()
- numpy.add()
- numpy.subtract()
- numpy.multiply()
- numpy.divide()
- numpy.sqrt()
- numpy.power()
- numpy.sum()
- numpy.prod()
- numpy.mean()
- numpy.std()
- numpy.min()
- numpy.max()
- numpy.save()
- numpy.load()
- numpy.savetxt()
- numpy.loadtxt()
- numpy.all()
- numpy.any()
代表的なメソッド以外は利用シーンは少ないですが、様々なパターンで計算メソッドが備えられています。
こちらもデータをお持ちでない人もサンプルデータを用意しているため、サンプルコードを確認してください。
特に、プログラミングを主体とする大学の学部・学科に所属している人は、numpyを利用することで結果を素早く求められます。
また、CSVやExcelにてデータをお持ちの人は、膨大な計算を一気に片付けたいあるいは計算方式をいくつも試したいといった場面で活躍します。
tkinterのサンプルコード
ここでは、以下の内容に関するtkinterのサンプルコードをまとめます。
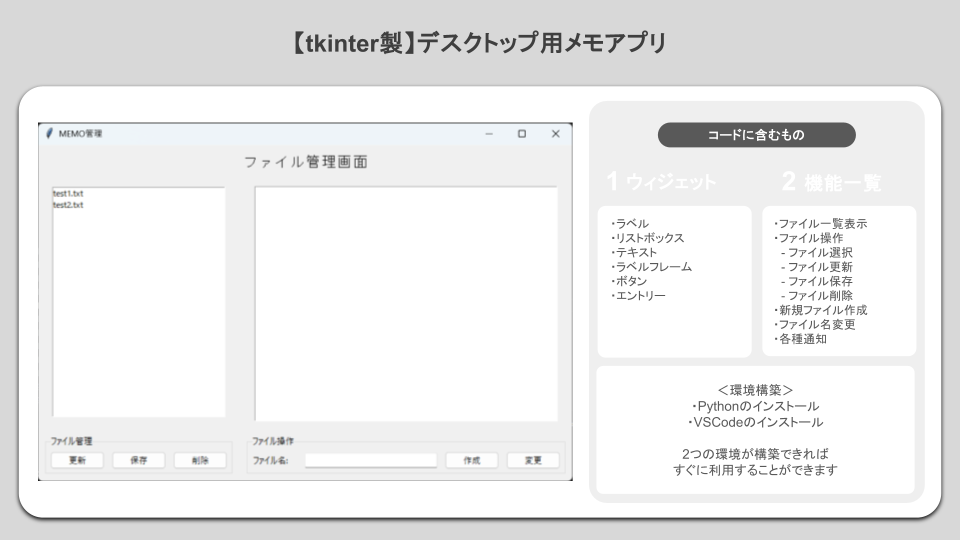
- 【tkinter製】デスクトップ用メモアプリ
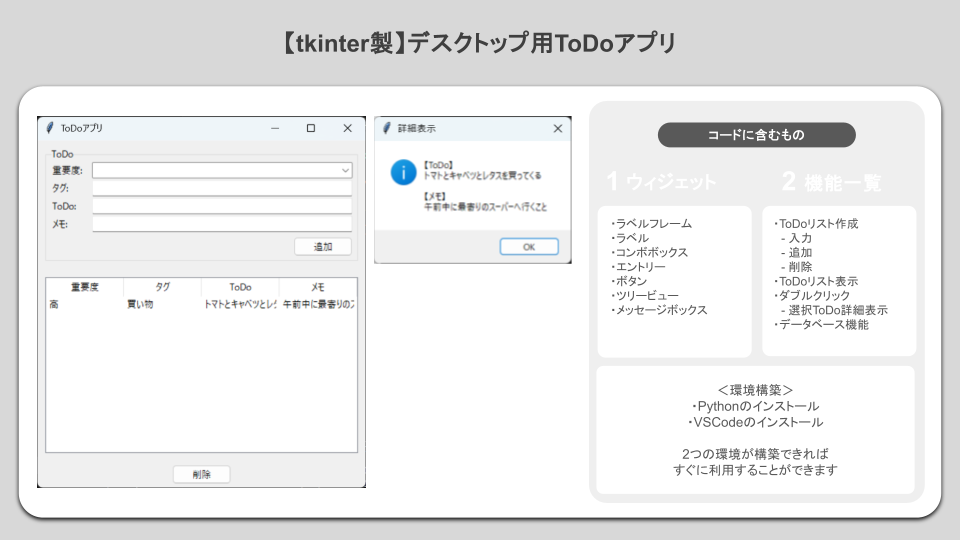
- 【tkinter製】デスクトップ用ToDoアプリ
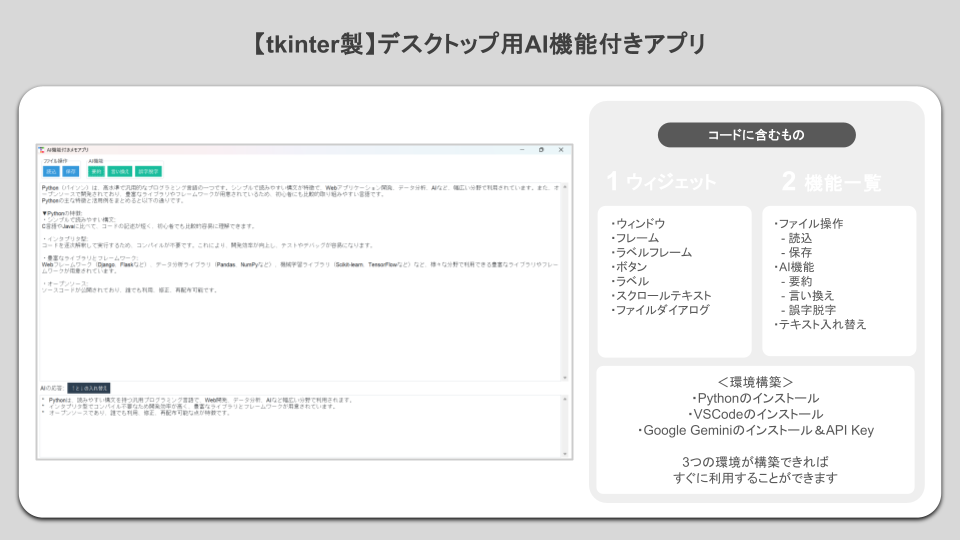
- 【tkinter製】デスクトップ用AI(Gemini)機能付きメモアプリ
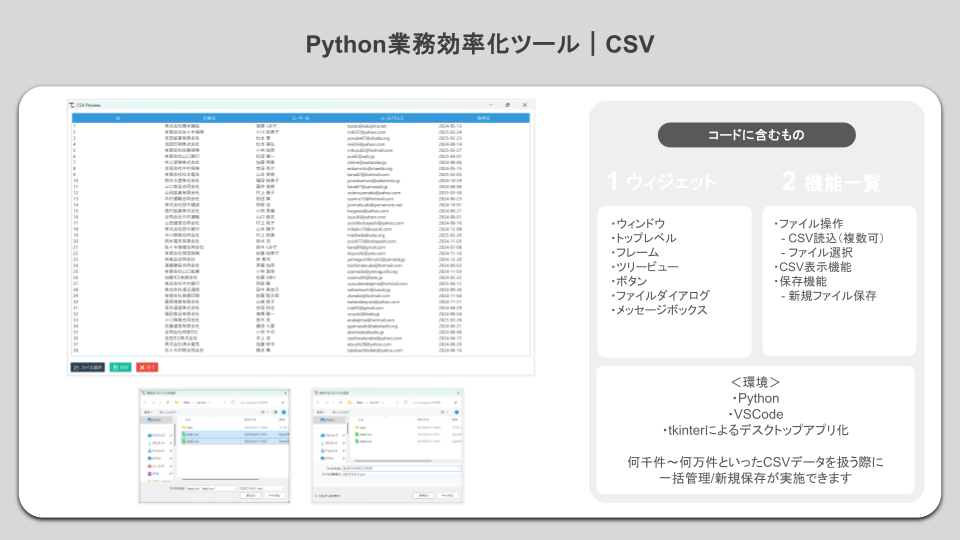
- Excel業務効率化ツール
- CSVファイル結合ツール
- Webサイト監視ツール
- GoogleMapsデータ収集ツール
デスクトップ用ライブラリであるtkinterを利用し、Pythonライブラリを活用したサンプルデスクトップアプリを用意しています。

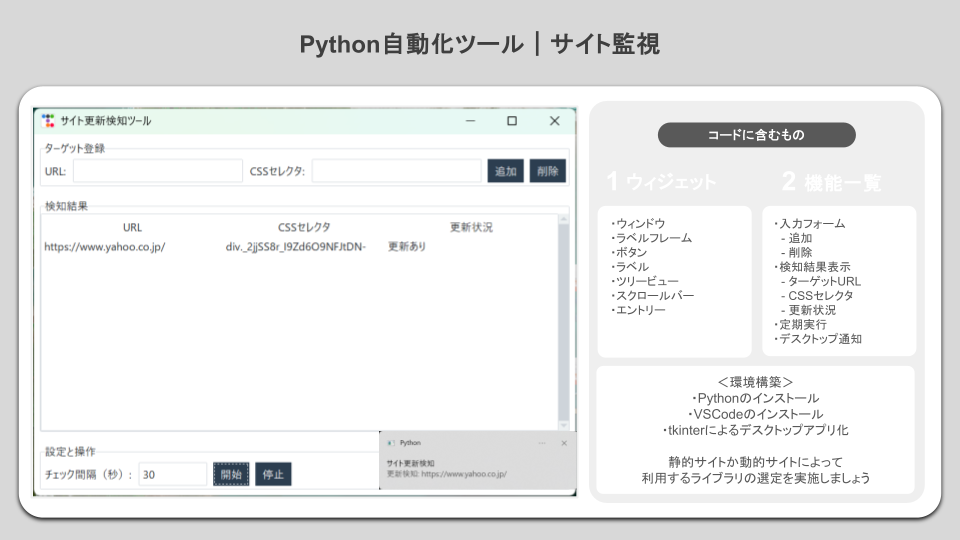

上記のデスクトップアプリ開発にあたって、Python用GUIライブラリガイドが欲しい人はぜひメルマガ登録から無料で受け取ってください。
\ メルアドのみで今すぐ受け取れます /
また、tkinterの各ウィジェット一覧や各ウィジェットの使い方をまとめた記事は以下になります。
各ウィジェットの引数も含めてサンプルコードを記載しているので、「【Python】tkinterの使い方&ウィジェット一覧表|GUIデスクトップアプリ開発」を一読ください。
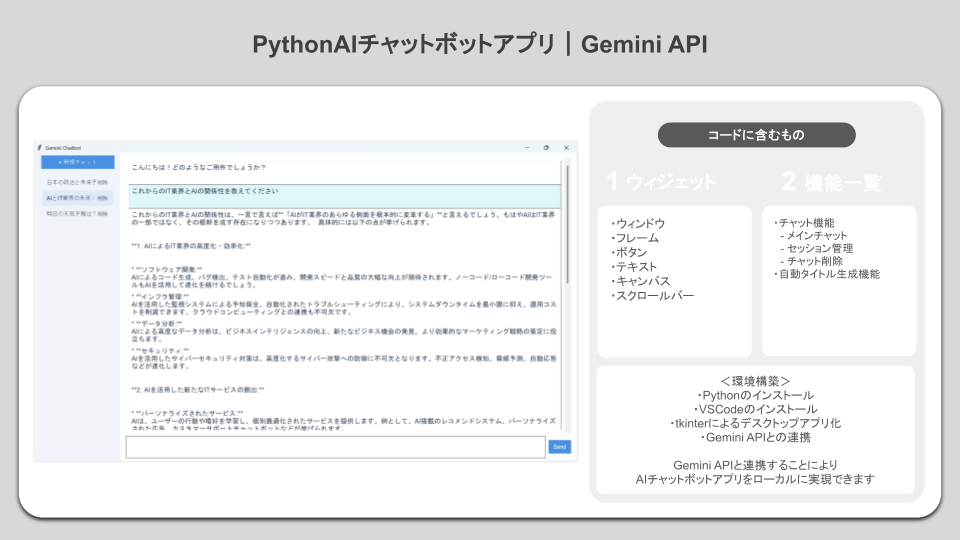
チャットボットのサンプルコード
ここでは、以下のチャットボットアプリをご紹介します。
- Gemini APIを利用したAIチャットボットアプリ
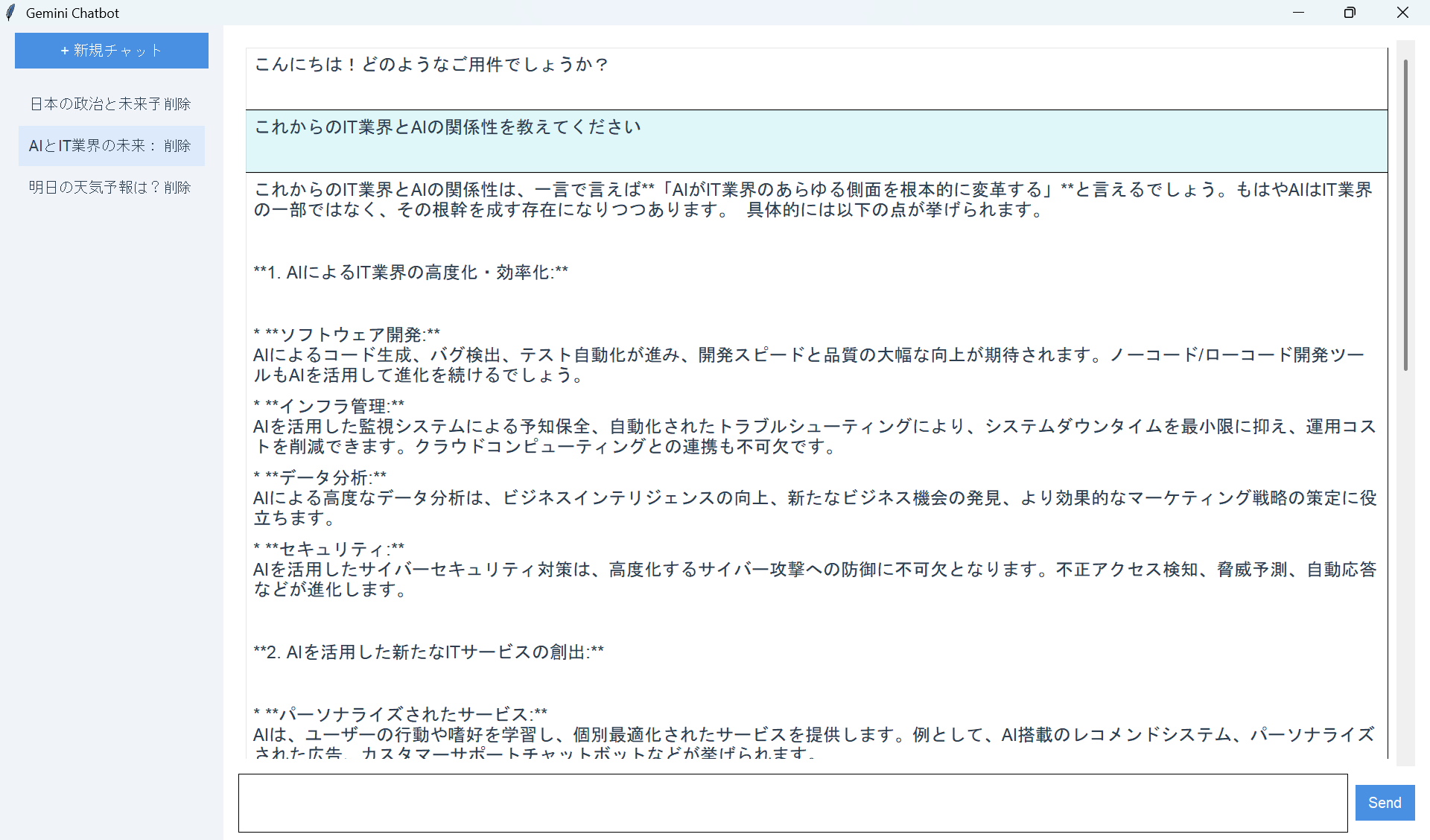
上記のデスクトップアプリ開発にあたって、Python用GUIライブラリガイドが欲しい人はぜひメルマガ登録から無料で受け取ってください。
\ メルアドのみで今すぐ受け取れます /
AIチャットボットアプリのUI実装と機能実装を詳しく理解したい人は「【Python】TkinterによるAIチャットボット開発とサンプルコード」を一読ください。
Pythonのフレームワークにおけるサンプルコード集
ここでは、Pythonで代表的なフレームワークを用いたサンプルコード集(参考記事含む)を紹介します。
概要になりますが、詳細なプログラムの解説や部分的説明を求める人は、ぜひ関連記事から一読ください。
以下は、Pythonで代表的なフレームワークのサンプルコード集になります。
- Flaskのサンプルコード
特に小規模アプリとはいえ膨大な解説とサンプルコード集になるため、各アプリ記事をお読み頂けると幸いです。
Flaskのサンプルコード
ここでは、以下の内容に関するFlaskのサンプルコードをまとめます。
- 最小限機能アプリ開発
- お問い合わせフォームアプリ開発
- 【Flask】flask-loginによるログイン機能を実装した認証アプリ開発
- 【Flask】画像ファイルアップロード機能を実装した画像表示アプリ開発
最小限機能アプリ開発
以下は、Flaskを利用した最小限機能アプリになります。
# Flaskをimport
from flask import Flask
# Flaskクラスをインスタンス化
app = Flask(__name__)
# URLと実行する関数をマッピング
@app.route("/")
def index():
return 'Hello World!'
Flaskのインストール方法から実行環境構築、アプリ開発時に知っておくFlask知識など確認したい人は「【Python】Flaskとは?インストール方法から開発環境構築まで解説!」を一読ください。
お問い合わせフォームアプリ開発
以下は、Flaskを利用したお問い合わせフォームアプリになります。
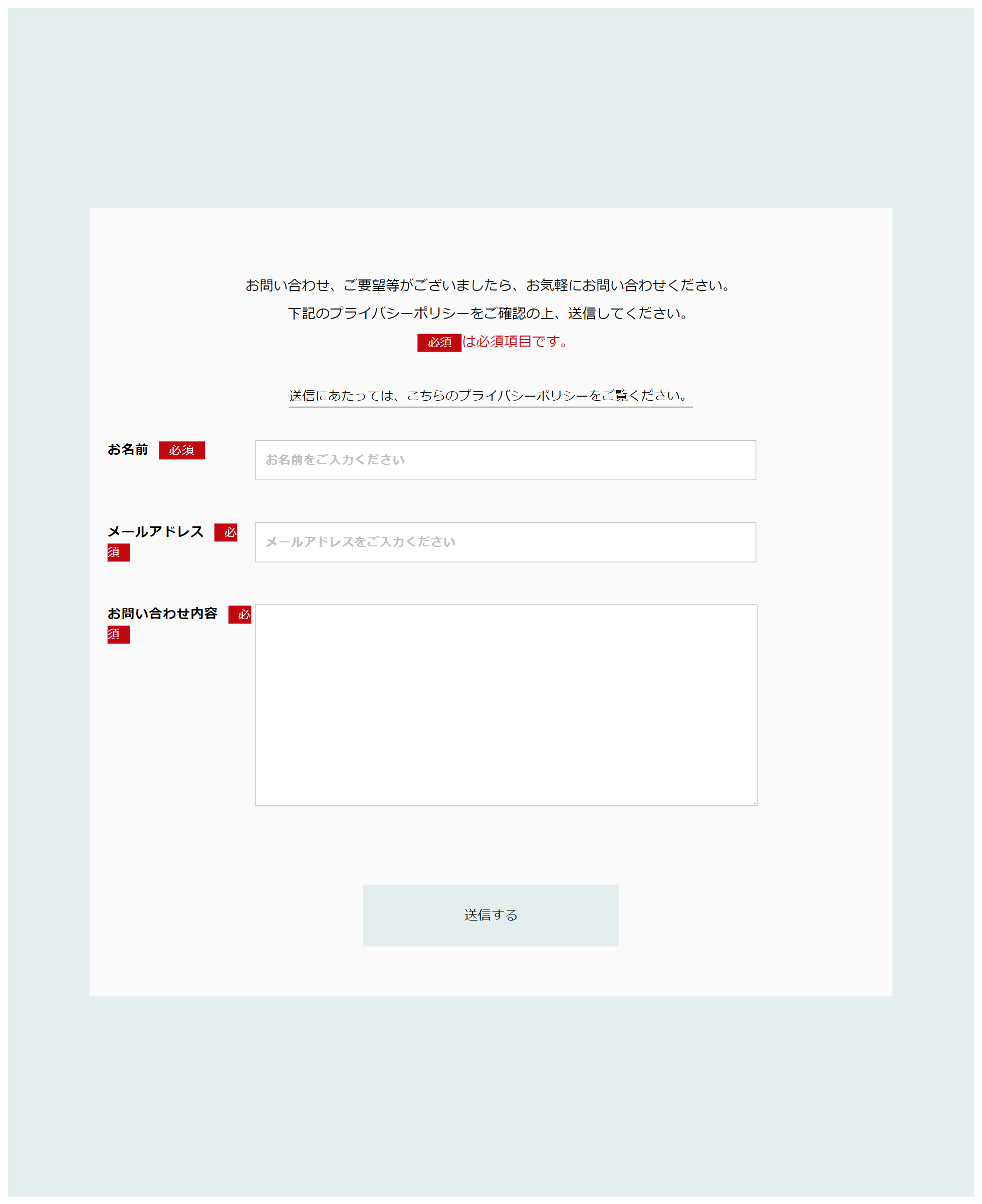

Flaskを利用したお問い合わせフォームアプリのサンプルコードを確認したい人は「Flaskによるrequest・redirectを利用したformの使い方」を一読ください。
flask-loginによるログイン機能を実装した認証アプリ開発
以下は、flask-loginによるログイン機能を実装した認証アプリになります。

flask-loginによるログイン機能を実装した認証アプリのサンプルコードを確認したい人は「【Flask】flask-loginによるログイン機能を実装した認証アプリ開発」を一読ください。
画像ファイルアップロード機能を実装した画像表示アプリ開発
以下は、画像ファイルアップロード機能を実装した画像表示アプリになります。

画像ファイルアップロード機能を実装した画像表示アプリのサンプルコードを確認したい人は「【Flask】画像ファイルアップロード機能を実装した画像表示アプリ開発」を一読ください。
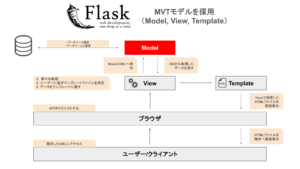
これからFlaskを学習してアプリ開発に挑戦したい人は、FlaskのMVTモデルの理解が必要です。

FlaskにおけるModelの役割
FlaskにおいてModelは以下の役割を持ちます。
- データベースを作成する
- データベースを操作する
つまり、Modelはデータベースのテーブルを定義することになります。
データベースを構築する際に必要な知識が以下の内容になります。
- flask-sqlalchemy
- flask-migrate
- SQLite
Modelの作成方法やデータベース構築方法を具体的に知りたい人は、「【Flask】Webアプリ開発におけるModelの役割」を一読ください。
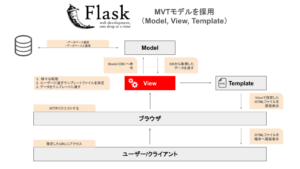
FlaskにおけるViewの役割
FlaskにおいてViewは以下の役割を持ちます。
- データベースを操作する
- PRGに基づいてルーティングとテンプレートを制御する
つまり、ViewはModelとTemplateを制御することになります。
Viewを実装する際に必要な知識が以下の内容になります。
- CRUD機能の理解
- ルーティングの理解
- PRG(Post/Redirect/Get)パターン
- render_template
- redirect
- url_for
- request
Viewの作成方法やデータベース/テンプレート制御を具体的に知りたい人は、「【Flask】Webアプリ開発におけるViewの役割」を一読ください。
FlaskにおけるTemplateの役割
FlaskにおいてTemplateは以下の役割を持ちます。
- ViewからTemplateへのデータの受け渡し
- ルーティング情報に沿ったテンプレート作成(各ページ)
- <a>タグ, <form>タグ, <button>タグが持つルートデザイン設計
- CSSによるUI/UXを意識したデザイン調整
つまり、Templateはユーザー行動を意識したデザインを考慮することになります。
Templateを実装する際に必要な知識が以下の内容になります。
- ルーティングの理解
- テンプレートエンジン(jinja2)の理解
- 共通テンプレートと継承
- データ出力のロジック設計
Templateの作成方法や共通化/継承など具体的に知りたい人は、「【Flask】Webアプリ開発におけるTemplateの役割」を一読ください。
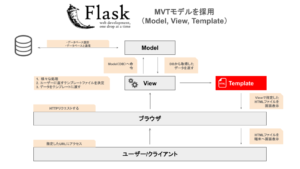
今後のPythonフレームワークによるWebアプリ開発を実施する上で、とても重要になるためぜひ一読頂けると幸いです。