Webスクレイピングを実施する中で、画像データに関する収集・保存するケースがあります。
本記事では、画像データ収集・保存を実施するWebスクレイピングについて解説します。
- Webスクレイピングとは
- requests&BeautifulSoupによる画像スクレイピング
▼【無料教材】Pythonを学びたい人へ資料を配布中▼
本記事をお読み頂いているプログラミング初学者向けに、本サイトはPythonを始めるためのガイドを配布しています。
以下に無料配布するPython資料をご紹介します。
- Python入門ガイド
- Python製デスクトップ用GUIライブラリガイド
- Python用学習ロードマップシート
- Tkinter製テンプレート集
- DXアイデア100選スライド
限られた時間を情報収集に極力かけず、他言語よりも「なぜ今Pythonを選ぶべきか」をガイドにしています。
プログラミングにおいて、情報収集の時間短縮は学習時間の短縮に直結します。
開発環境→基礎学習→ライブラリ/FW→アプリ開発に至る学習シートを配布しています。
また、定期アンケートによって「リアルな声」を反映して常に教材改善のアップデート情報を受け取れます。
\ メルアドのみで今すぐ受け取れます /
Webスクレイピングとは

Webスクレイピングとは、主にサイトからデータを収集する技術を指します。
当然、画像データも含まれるため、スクレイピング技術でデータ収集・保存が可能です。
画像データスクレイピング実施の準備
2章では、以下の方法で画像データのスクレイピングを実施します。
- 自身のPCにダウンロードフォルダ作成
- https://images.search.yahoo.com/を利用(検索エンジンはGoogle)
- 検索キーワードから特定の各画像を一括でダウンロード
- フォルダ内にファイル名を付けて保存
上記の手順で画像データのスクレイピングを実施します。
requestsのメソッドの使い方
ここでは、画像スクレイピング時に利用するrequestsライブラリの概要を解説します。
requestsでは、以下の4つが代表的なメソッドになります。
| メソッド名 | 説明 |
|---|---|
| requests.get() | サーバーから情報を取得 |
| requests.post() | サーバーへ情報を送信 |
| requests.put() | サーバーの情報を更新 |
| requests.delete() | サーバーの情報を削除 |
本記事では、画像URLに対してWebスクレイピングを利用するため、.get()メソッドを重点的に解説します。
requests.get()の引数の使い方
Webスクレイピングといったデータ収集などで頻繁に利用されるのがrequests.get()になります。
res = requests.get(URL, 任意の引数).get()メソッドを利用することで直感的に操作することができます。
また、以下が主な引数になります。
| メソッド名 | 必須/任意 | 説明 |
|---|---|---|
| URL | 必須 | 対象URL |
| headers | 任意 | リクエスト時にヘッダーデータを辞書で指定 |
| params | 任意 | リクエスト時にURLのクエリパラメータを辞書で指定 |
| cookies | 任意 | リクエスト時にクッキーを辞書で指定 |
| timeout | 任意 | リクエスト時のタイムアウトを指定 |
スクレイピング業務では、引数にURLのみを利用することが多いです。
requests.get()によるresponseオブジェクトの確認
リクエスト後の戻り値(応答)として、responseオブジェクトが返ってきます。
以下がresponseオブジェクトの属性値になります。
| 属性 | 説明 |
|---|---|
| status_code | ステータスコード |
| headers | レスポンスヘッダーのデータ |
| content | レスポンスのバイナリデータ |
| text | レスポンスのテキストデータ |
| encoding | エンコーディング(変換方式:utf-8など) |
| cookies | クッキーデータ |
ここでは、responseオブジェクトのtext属性データのみを利用する画像スクレイピングプログラムになります。
requestsライブラリをさらに理解したい人は、「【データ収集に役立つ】requestsとは?インストールから使い方まで徹底解説!」を一読ください。

BeautifulSoupの代表的なメソッドの使い方
HTMLデータを解析した後、指定した箇所のデータを抽出する必要があります。
本記事では、スクレイピングの際に利用するBeautifulSoupの代表的なメソッドを記載します。
| タイプ | 1要素だけ返す | 全要素をリストで返す | 引数(検索条件指定) |
|---|---|---|---|
| find系 | find() | find_all() | 要素名, 属性指定(キーワード引数) |
| select系 | select_one() | select() | CSSセレクタ |
機能はどちらも同じですが、引数の違いによって探し出すアプローチ方法が異なります。
ただし、HTMLデータによってはクラス/idに対して属性値を持たないデータがあるため、その場合はselect系を利用しましょう。
BeautifulSoupをさらに理解したい人は、「【チートシート】BeautifulSoup4とは?インストールから使い方まで徹底解説!」を一読ください。

requests&BeautifulSoupによる画像スクレイピング
それでは、実際にプログラムを作成する上で手順を解説します。
- ダウンロードフォルダ作成
- 画像スクレイピングに必要なライブラリのインポート
- requestsにてサイトの検索結果URLにアクセスし情報取得
- BeautifulSoupにてサイト情報の解析
- imgタグから画像URLのみ抽出
- 各画像URLから画像ダウンロード
- ダウンロードした画像をフォルダに保存
上記内容を手順ごとに作成していきます。
ダウンロードフォルダ作成
こちらは、PC内で任意のディレクトリにてダウンロードフォルダを作成してください。
また、スクリプトファイルも利用するため、以下の階層フォルダで作成しています。
scraping-imageフォルダ
├ scraping-image.py
└ downloadフォルダ上記のフォルダ構成で進めていきます。
画像スクレイピングに必要なライブラリのインポート
2章では、上述通りrequestsとBeautifulSoupをライブラリとしてインポートします。
pip install requests
pip install bs4まだライブラリのインストールが済んでいない人は、上記のコードでインストールを実行してください。
Macであればターミナル、Windowsであればコマンドプロンプトでインストールコマンドを実行できます。
import os
import requests
from bs4 import BeautifulSoup上記のコードをscraping-image.pyに記載します。
osモジュールは、フォルダに画像ダウンロードする際、パス指定等を利用するためインポートしています。
requestsにてサイトの検索結果URLにアクセスし情報取得
ここでは、「python logo」を検索キーワードにしています。
気になる画像検索ワードがあれば、任意で検索結果を表示させましょう。
page_url = "検索結果のURLを貼り付け"
res = requests.get(page_url)上記のコードでは、page_url変数にURLを代入しています。
また、res変数に.getメソッドを利用し任意のURLへアクセス&情報取得を実施しています。
BeautifulSoupにてサイト情報の解析
取得したサイト情報をBeautifulSoupにて解析します。
soup = BeautifulSoup(res.text)上記コードでは、soup変数にBeautifulSoupモジュールを利用し、res変数内のサイト情報をテキストデータに変換しています。
print(soup.find_all("img"))上記のprint関数を利用することで、取得データを確認できます。
また、.find_allメソッドを利用し、imgタグが付与されているサイト情報のみを抽出しています。
imgタグから画像URLのみ抽出
ここから、解析したサイト情報からimgタグが付与された要素のみを抽出していきます。
img_tags = soup.find_all("img")先ほどのprint関数と同様、.find_allメソッドを活用しています。
img_tagsリスト変数は、この後for文を活用しリスト内を繰り返し処理させます。
img_urls = []ここでimg_urlsリスト変数を宣言しておきます。
for文で繰り返し処理を実行した際に、抽出した各URLをリスト型データとして格納するためです。
for img_tag in img_tags:
img_url = img_tag.get("src")
if img_url != None:
img_urls.append(img_url)for文を用いてimg_tagsリスト変数を繰り返し処理させます。
この際、pythonはmリストデータをindex順に処理するため、index順に格納されているデータを取得し、img_tag変数として処理します。
処理の中では、img_tag変数に.getメソッドを活用し、srcタグが付与されている要素(つまりURLデータ)を抽出します。
if文では、img_urlのデータ有無を確認し、データが存在すればimg_urlsリスト変数に格納する処理になります。
各画像URLから画像ダウンロード
download_folder = "download"予め作成しておいたフォルダ名を変数に格納しています。
このフォルダ内に各画像がダウンロードされます。
for i, img_url in enumerate(img_urls):
img = requests.get(img_url, stream=True)
# ファイル名を番号順にするために、インデックスを利用
img_name = f"image_{i}.jpg"
# ダウンロードフォルダに保存するパスを作成
save_path = os.path.join(download_folder, img_name)for文を利用し、リストデータであるimg_urlsを処理しています。
また、enumerate関数をfor文で利用することで、リストデータをカウントします。(カウント数はiに格納)
img変数にて画像データを取得しています。
また、ファイル名を統一させ、カウント数を付与しています。
osモジュールを利用し、ダウンロードフォルダ内に保存するパスを作成しています。
ダウンロードした画像をフォルダに保存
最後に、ダウンロードした画像をフォルダに保存する処理を記述します。
with open(save_path, "wb") as f:
f.write(img.content)
print(f"画像をダウンロードしました: {save_path}")with open関数を利用することで、指定したフォルダへ任意のファイルを格納します。
スクレイピングコード(全体)
import os
import requests
from bs4 import BeautifulSoup
page_url = "検索結果のURLを貼り付け"
res = requests.get(page_url)
soup = BeautifulSoup(res.text)
print(soup.find_all("img"))
img_tags = soup.find_all("img")
img_urls = []
for img_tag in img_tags:
img_url = img_tag.get("src")
if img_url != None:
img_urls.append(img_url)
download_folder = "download"
for i, img_url in enumerate(img_urls):
img = requests.get(img_url, stream=True)
# ファイル名を番号順にするために、インデックスを利用
img_name = f"image_{i}.jpg"
# ダウンロードフォルダに保存するパスを作成
save_path = os.path.join(download_folder, img_name)
with open(save_path, "wb") as f:
f.write(img.content)
print(f"画像をダウンロードしました: {save_path}")実行結果
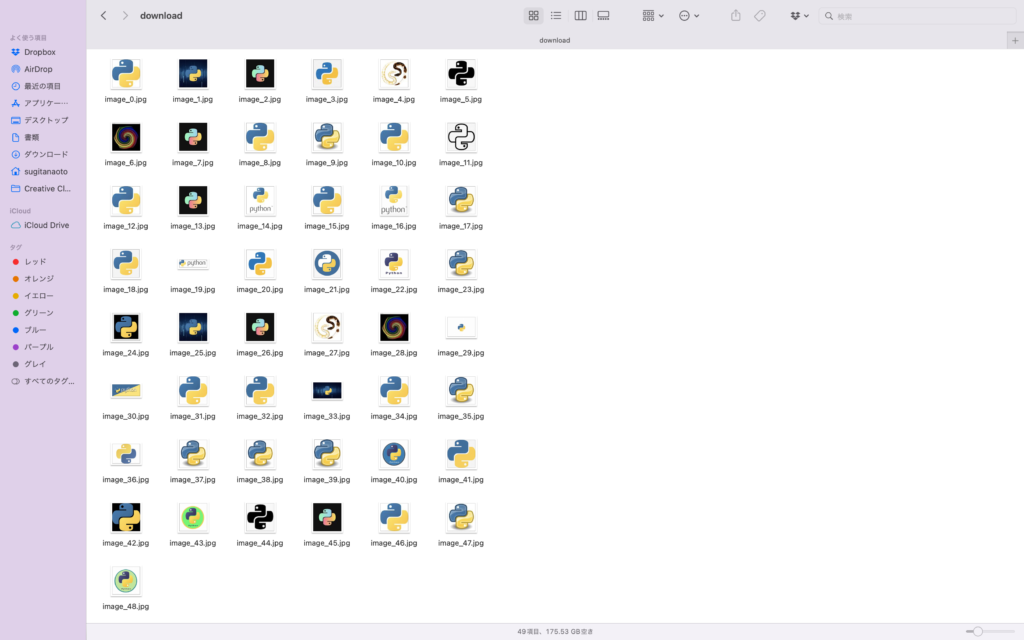
Google画像検索で収集・保存・取得するには?
基本的に、2章で記載したプログラムを利用してGoogle検索でも画像収集できます。(実施済み)
ただ、以下のGoogle画像検索時の課題と解決策が挙げられます。
| Google画像検索時の課題 | Google画像検索時の解決策 |
|---|---|
| ・動的ページであるため、画面操作が必須 ・src内のURLでエラーが発生するため、try-except文が必要 | ・Seleniumライブラリによる画面操作の処理を追加 ・エラー処理の追加 |
ブラウザ操作による読み込みが処理に追加できれば、全画像取得プログラムが作成できます。
Seleniumにおける各メソッドの使い方を詳細に知りたい人は、「【業務自動化】Seleniumとは?インストールから使い方まで徹底解説!」を一読ください。

画像スクレイピングの留意点
当然ですが、プログラムによる画像スクレイピングにはいくつかの留意点があります。
- 対象とするサイトの利用規約を確認する
- 対象とするサイトのサーバー負荷を考慮する
- プライバシーと倫理観を考慮する
特に、画像検索のキーワードによっては対象サイトへの配慮が必要になります。
また、プライバシー侵害やスクレイピング利用者の倫理観によって画像の取り扱いも十分に気を付ける必要があるでしょう。
画像スクレイピングによる活用事例
昨今では、生成AIサービスの台頭により膨大な機械学習モデルが存在しています。
その中で、大量画像データを利用した資料作成や機械学習モデルそのものの学習に利用するのが有名な活用事例になります。
ただし、同時に法的な観点や倫理的な観点には十分な注意を払い実施しましょう。